TIM: Teaching Large Language Models to Translate with Comparison
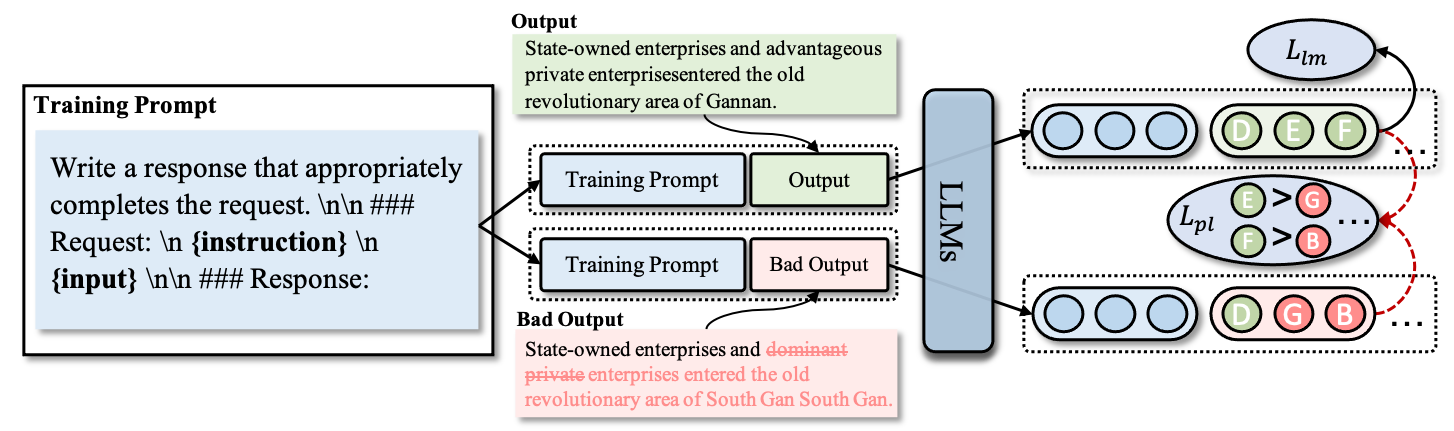
Open-sourced large language models (LLMs) have demonstrated remarkable efficacy in various tasks with instruction tuning. However, these models can sometimes struggle with tasks that require more specialized knowledge such as translation. One possible reason for such deficiency is that instruction tuning aims to generate fluent and coherent text that continues from a given instruction without being constrained by any task-specific requirements. Moreover, it can be more challenging for tuning smaller LLMs with lower-quality training data. To address this issue, we propose a novel framework using examples in comparison to teach LLMs to learn translation. Our approach involves presenting the model with examples of correct and incorrect translations and using a preference loss to guide the model's learning. We evaluate our method on WMT2022 test sets and show that it outperforms existing methods. Our findings offer a new perspective on fine-tuning LLMs for translation tasks and provide a promising solution for generating high-quality translations. Please refer to Github for more details: https://github.com/lemon0830/TIM.
PDF Abstract

