Three Ways of Using Large Language Models to Evaluate Chat
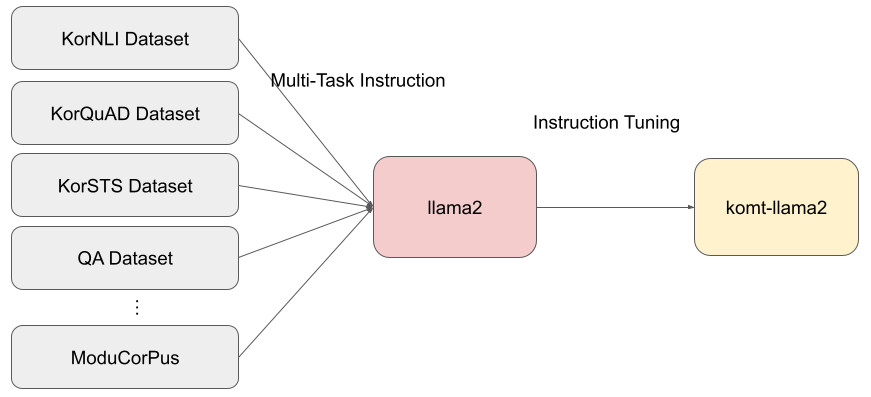
This paper describes the systems submitted by team6 for ChatEval, the DSTC 11 Track 4 competition. We present three different approaches to predicting turn-level qualities of chatbot responses based on large language models (LLMs). We report improvement over the baseline using dynamic few-shot examples from a vector store for the prompts for ChatGPT. We also analyze the performance of the other two approaches and report needed improvements for future work. We developed the three systems over just two weeks, showing the potential of LLMs for this task. An ablation study conducted after the challenge deadline shows that the new Llama 2 models are closing the performance gap between ChatGPT and open-source LLMs. However, we find that the Llama 2 models do not benefit from few-shot examples in the same way as ChatGPT.
PDF Abstract
 Colab
Colab

 DailyDialog
DailyDialog
