The Unreasonable Effectiveness of Deep Features as a Perceptual Metric
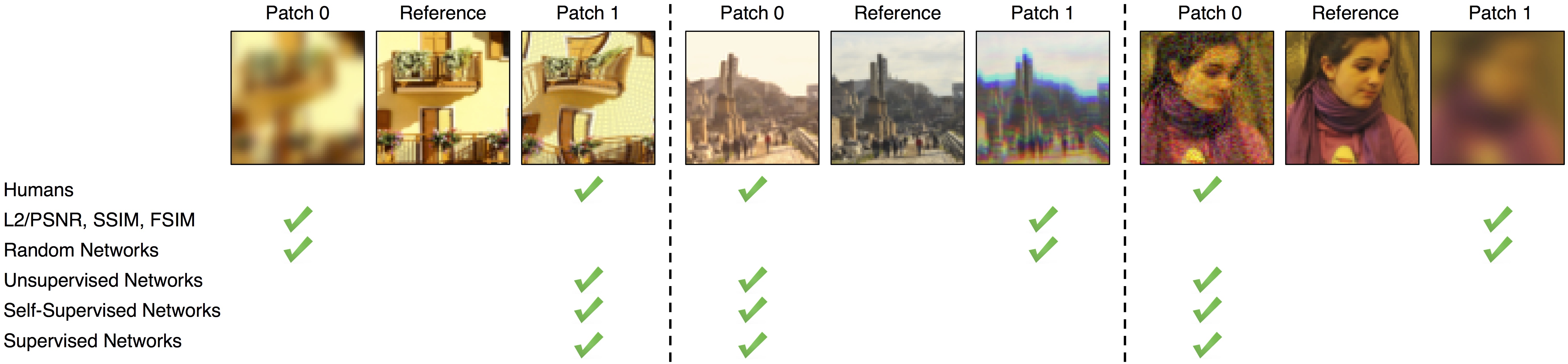
While it is nearly effortless for humans to quickly assess the perceptual similarity between two images, the underlying processes are thought to be quite complex. Despite this, the most widely used perceptual metrics today, such as PSNR and SSIM, are simple, shallow functions, and fail to account for many nuances of human perception. Recently, the deep learning community has found that features of the VGG network trained on ImageNet classification has been remarkably useful as a training loss for image synthesis. But how perceptual are these so-called "perceptual losses"? What elements are critical for their success? To answer these questions, we introduce a new dataset of human perceptual similarity judgments. We systematically evaluate deep features across different architectures and tasks and compare them with classic metrics. We find that deep features outperform all previous metrics by large margins on our dataset. More surprisingly, this result is not restricted to ImageNet-trained VGG features, but holds across different deep architectures and levels of supervision (supervised, self-supervised, or even unsupervised). Our results suggest that perceptual similarity is an emergent property shared across deep visual representations.
PDF Abstract CVPR 2018 PDF CVPR 2018 AbstractCode


 Colab
Colab

Datasets
Introduced in the Paper:
 Perceptual Similarity
Perceptual Similarity
Used in the Paper:
CSIQ MSU SR-QA Dataset MSU NR VQA Database
MSU NR VQA Database
 MSU FR VQA Database
MSU FR VQA Database

