The Lottery Ticket Hypothesis for Pre-trained BERT Networks
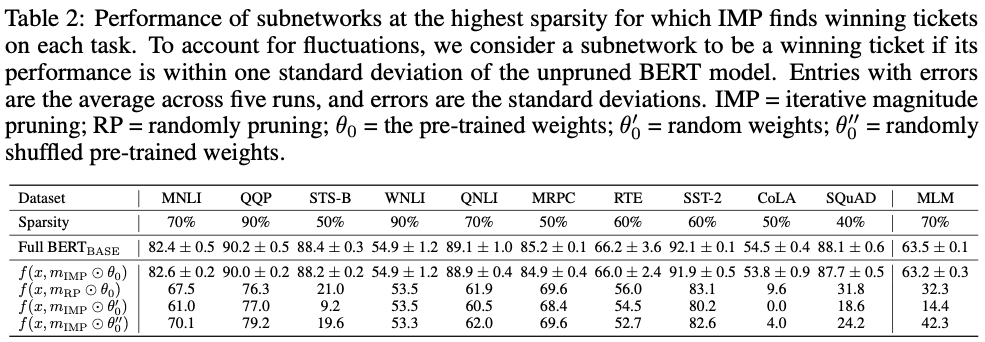
In natural language processing (NLP), enormous pre-trained models like BERT have become the standard starting point for training on a range of downstream tasks, and similar trends are emerging in other areas of deep learning. In parallel, work on the lottery ticket hypothesis has shown that models for NLP and computer vision contain smaller matching subnetworks capable of training in isolation to full accuracy and transferring to other tasks. In this work, we combine these observations to assess whether such trainable, transferrable subnetworks exist in pre-trained BERT models. For a range of downstream tasks, we indeed find matching subnetworks at 40% to 90% sparsity. We find these subnetworks at (pre-trained) initialization, a deviation from prior NLP research where they emerge only after some amount of training. Subnetworks found on the masked language modeling task (the same task used to pre-train the model) transfer universally; those found on other tasks transfer in a limited fashion if at all. As large-scale pre-training becomes an increasingly central paradigm in deep learning, our results demonstrate that the main lottery ticket observations remain relevant in this context. Codes available at https://github.com/VITA-Group/BERT-Tickets.
PDF Abstract NeurIPS 2020 PDF NeurIPS 2020 Abstract


 GLUE
GLUE
 QNLI
QNLI
