The Assistive Multi-Armed Bandit
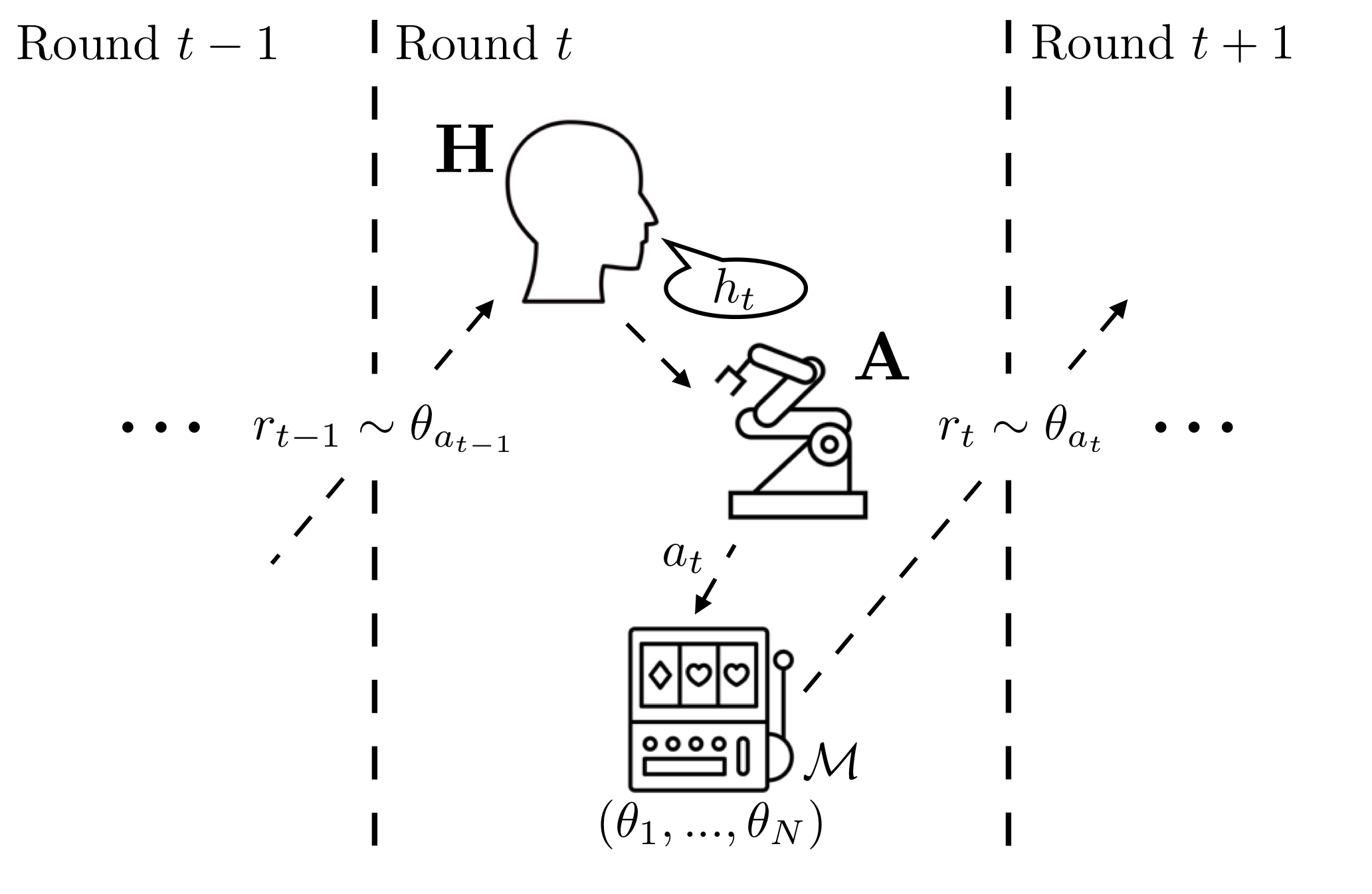
Learning preferences implicit in the choices humans make is a well studied problem in both economics and computer science. However, most work makes the assumption that humans are acting (noisily) optimally with respect to their preferences. Such approaches can fail when people are themselves learning about what they want. In this work, we introduce the assistive multi-armed bandit, where a robot assists a human playing a bandit task to maximize cumulative reward. In this problem, the human does not know the reward function but can learn it through the rewards received from arm pulls; the robot only observes which arms the human pulls but not the reward associated with each pull. We offer sufficient and necessary conditions for successfully assisting the human in this framework. Surprisingly, better human performance in isolation does not necessarily lead to better performance when assisted by the robot: a human policy can do better by effectively communicating its observed rewards to the robot. We conduct proof-of-concept experiments that support these results. We see this work as contributing towards a theory behind algorithms for human-robot interaction.
PDF Abstract

