Text-Only Training for Image Captioning using Noise-Injected CLIP
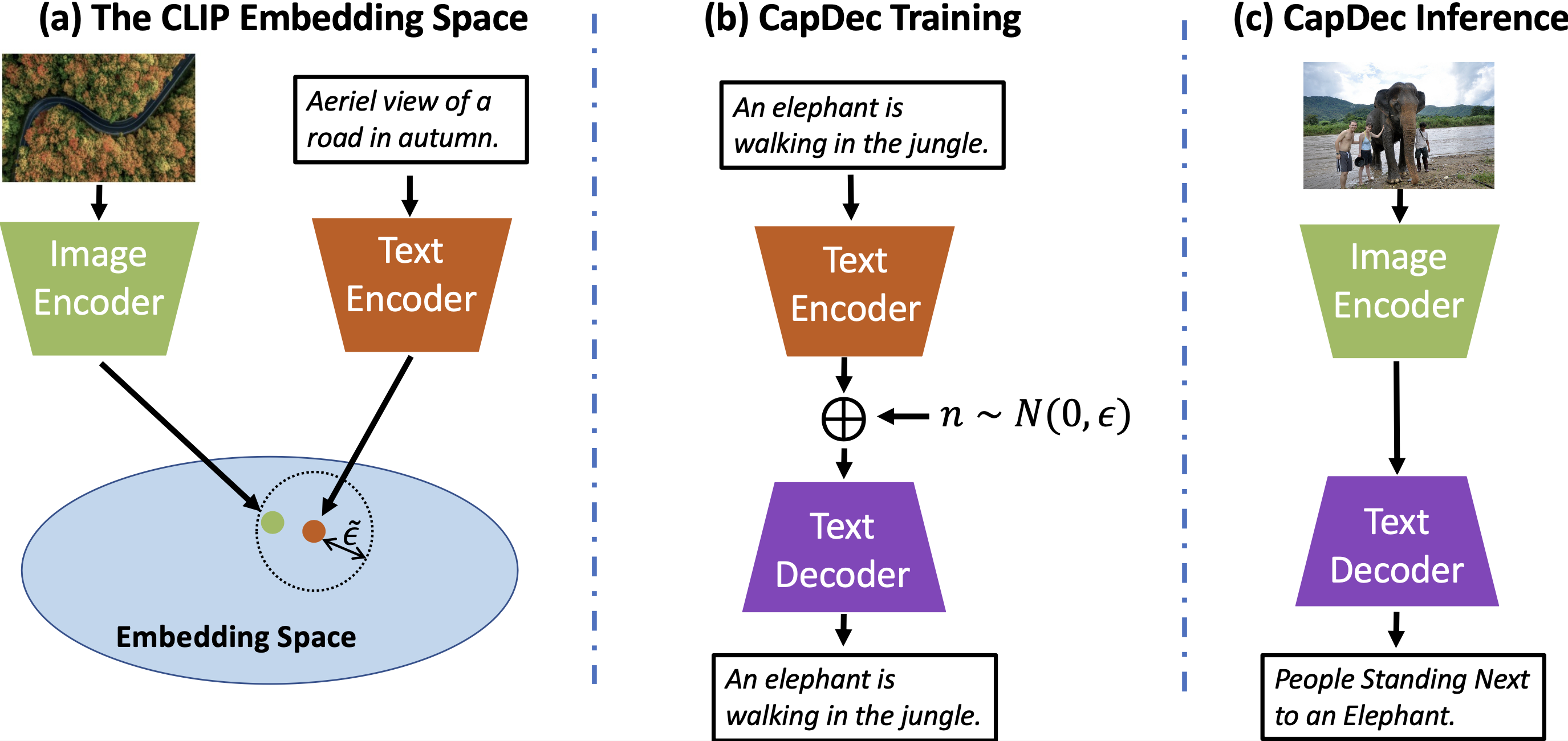
We consider the task of image-captioning using only the CLIP model and additional text data at training time, and no additional captioned images. Our approach relies on the fact that CLIP is trained to make visual and textual embeddings similar. Therefore, we only need to learn how to translate CLIP textual embeddings back into text, and we can learn how to do this by learning a decoder for the frozen CLIP text encoder using only text. We argue that this intuition is "almost correct" because of a gap between the embedding spaces, and propose to rectify this via noise injection during training. We demonstrate the effectiveness of our approach by showing SOTA zero-shot image captioning across four benchmarks, including style transfer. Code, data, and models are available on GitHub.
PDF AbstractCode
 Colab
Colab




Datasets
 MS COCO
MS COCO
 Flickr30k
Flickr30k
 COCO Captions
COCO Captions
 FlickrStyle10K
FlickrStyle10K

| Task | Dataset | Model | Metric Name | Metric Value | Global Rank | Benchmark |
|---|---|---|---|---|---|---|
| Image Captioning | COCO Captions | CapDec | BLEU-4 | 26.4 | # 31 | |
| METEOR | 25.1 | # 26 | ||||
| CIDER | 91.8 | # 32 | ||||
| Semi Supervised Learning for Image Captioning | Flickr30k | CapDec | CIDEr | 39.1 | # 1 | |
| Image Captioning | FlickrStyle10K | CapDec | BLEU-1 (Romantic) | 29.4 | # 1 | |
| Semi Supervised Learning for Image Captioning | FlickrStyle10K | CapDec | CIDEr | 30.0 | # 1 | |
| Image Captioning | MSCOCO | CapDec | BLEU-4 | 26.4 | # 1 |
