Tem-adapter: Adapting Image-Text Pretraining for Video Question Answer
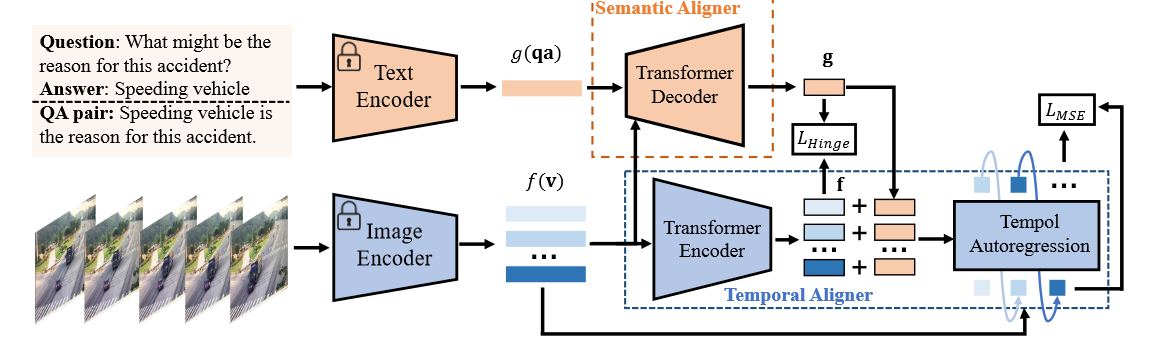
Video-language pre-trained models have shown remarkable success in guiding video question-answering (VideoQA) tasks. However, due to the length of video sequences, training large-scale video-based models incurs considerably higher costs than training image-based ones. This motivates us to leverage the knowledge from image-based pretraining, despite the obvious gaps between image and video domains. To bridge these gaps, in this paper, we propose Tem-Adapter, which enables the learning of temporal dynamics and complex semantics by a visual Temporal Aligner and a textual Semantic Aligner. Unlike conventional pretrained knowledge adaptation methods that only concentrate on the downstream task objective, the Temporal Aligner introduces an extra language-guided autoregressive task aimed at facilitating the learning of temporal dependencies, with the objective of predicting future states based on historical clues and language guidance that describes event progression. Besides, to reduce the semantic gap and adapt the textual representation for better event description, we introduce a Semantic Aligner that first designs a template to fuse question and answer pairs as event descriptions and then learns a Transformer decoder with the whole video sequence as guidance for refinement. We evaluate Tem-Adapter and different pre-train transferring methods on two VideoQA benchmarks, and the significant performance improvement demonstrates the effectiveness of our method.
PDF Abstract ICCV 2023 PDF ICCV 2023 Abstract


 MSR-VTT
MSR-VTT
 SUTD-TrafficQA
SUTD-TrafficQA

