TEACHTEXT: CrossModal Generalized Distillation for Text-Video Retrieval
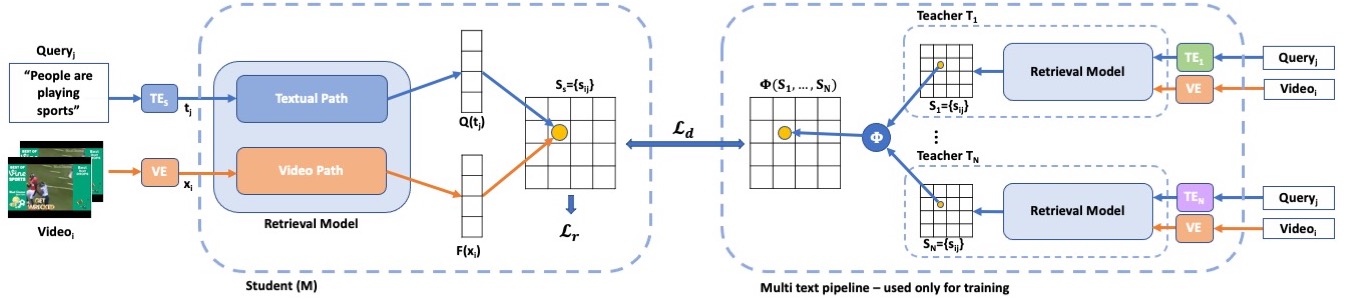
In recent years, considerable progress on the task of text-video retrieval has been achieved by leveraging large-scale pretraining on visual and audio datasets to construct powerful video encoders. By contrast, despite the natural symmetry, the design of effective algorithms for exploiting large-scale language pretraining remains under-explored. In this work, we are the first to investigate the design of such algorithms and propose a novel generalized distillation method, TeachText, which leverages complementary cues from multiple text encoders to provide an enhanced supervisory signal to the retrieval model. Moreover, we extend our method to video side modalities and show that we can effectively reduce the number of used modalities at test time without compromising performance. Our approach advances the state of the art on several video retrieval benchmarks by a significant margin and adds no computational overhead at test time. Last but not least, we show an effective application of our method for eliminating noise from retrieval datasets. Code and data can be found at https://www.robots.ox.ac.uk/~vgg/research/teachtext/.
PDF Abstract ICCV 2021 PDF ICCV 2021 Abstract

 ActivityNet
ActivityNet
 MSVD
MSVD
 DiDeMo
DiDeMo
 LSMDC
LSMDC
 VATEX
VATEX
