TDN: Temporal Difference Networks for Efficient Action Recognition
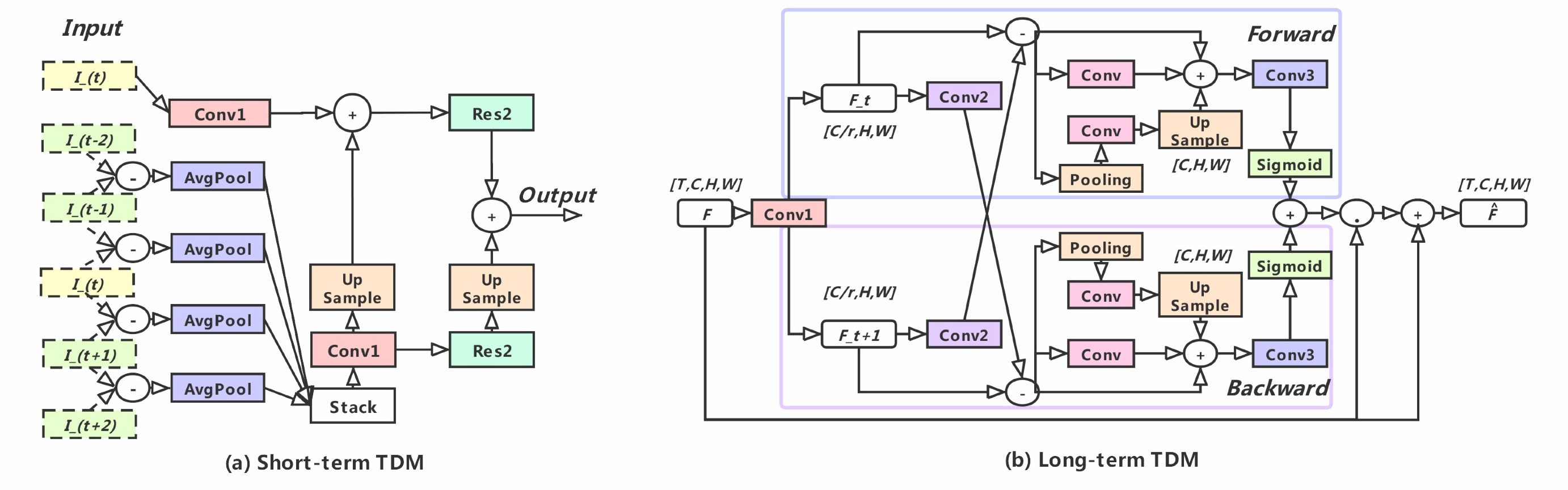
Temporal modeling still remains challenging for action recognition in videos. To mitigate this issue, this paper presents a new video architecture, termed as Temporal Difference Network (TDN), with a focus on capturing multi-scale temporal information for efficient action recognition. The core of our TDN is to devise an efficient temporal module (TDM) by explicitly leveraging a temporal difference operator, and systematically assess its effect on short-term and long-term motion modeling. To fully capture temporal information over the entire video, our TDN is established with a two-level difference modeling paradigm. Specifically, for local motion modeling, temporal difference over consecutive frames is used to supply 2D CNNs with finer motion pattern, while for global motion modeling, temporal difference across segments is incorporated to capture long-range structure for motion feature excitation. TDN provides a simple and principled temporal modeling framework and could be instantiated with the existing CNNs at a small extra computational cost. Our TDN presents a new state of the art on the Something-Something V1 & V2 datasets and is on par with the best performance on the Kinetics-400 dataset. In addition, we conduct in-depth ablation studies and plot the visualization results of our TDN, hopefully providing insightful analysis on temporal difference modeling. We release the code at https://github.com/MCG-NJU/TDN.
PDF Abstract CVPR 2021 PDF CVPR 2021 Abstract



 Kinetics
Kinetics
 Kinetics 400
Kinetics 400
 Something-Something V2
Something-Something V2
 Something-Something V1
Something-Something V1

