SynthCLIP: Are We Ready for a Fully Synthetic CLIP Training?
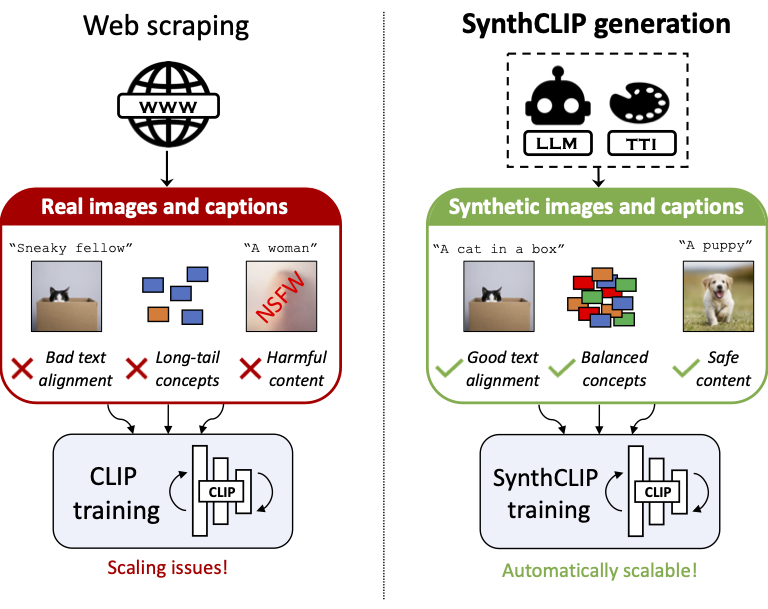
We present SynthCLIP, a novel framework for training CLIP models with entirely synthetic text-image pairs, significantly departing from previous methods relying on real data. Leveraging recent text-to-image (TTI) generative networks and large language models (LLM), we are able to generate synthetic datasets of images and corresponding captions at any scale, with no human intervention. With training at scale, SynthCLIP achieves performance comparable to CLIP models trained on real datasets. We also introduce SynthCI-30M, a purely synthetic dataset comprising 30 million captioned images. Our code, trained models, and generated data are released at https://github.com/hammoudhasan/SynthCLIP
PDF AbstractCode

Tasks
 CIFAR-10
CIFAR-10
 MS COCO
MS COCO
 CIFAR-100
CIFAR-100
 Oxford 102 Flower
Oxford 102 Flower
 Flickr30k
Flickr30k
 DTD
DTD
 Food-101
Food-101
 Caltech-101
Caltech-101
 CC12M
CC12M
Results from the Paper
Submit
results from this paper
to get state-of-the-art GitHub badges and help the
community compare results to other papers.
