SynCDR : Training Cross Domain Retrieval Models with Synthetic Data
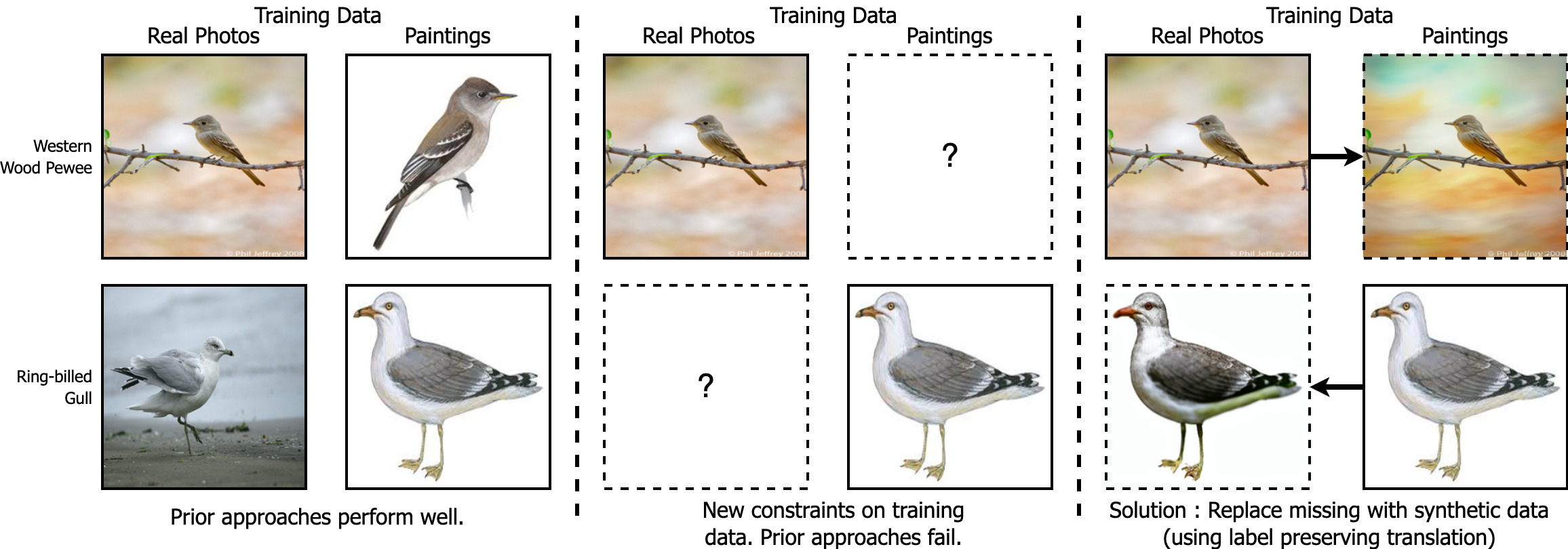
In cross-domain retrieval, a model is required to identify images from the same semantic category across two visual domains. For instance, given a sketch of an object, a model needs to retrieve a real image of it from an online store's catalog. A standard approach for such a problem is learning a feature space of images where Euclidean distances reflect similarity. Even without human annotations, which may be expensive to acquire, prior methods function reasonably well using unlabeled images for training. Our problem constraint takes this further to scenarios where the two domains do not necessarily share any common categories in training data. This can occur when the two domains in question come from different versions of some biometric sensor recording identities of different people. We posit a simple solution, which is to generate synthetic data to fill in these missing category examples across domains. This, we do via category preserving translation of images from one visual domain to another. We compare approaches specifically trained for this translation for a pair of domains, as well as those that can use large-scale pre-trained text-to-image diffusion models via prompts, and find that the latter can generate better replacement synthetic data, leading to more accurate cross-domain retrieval models. Our best SynCDR model can outperform prior art by up to 15\%. Code for our work is available at https://github.com/samarth4149/SynCDR .
PDF Abstract

 CUB-200-2011
CUB-200-2011
 Office-Home
Office-Home
 DomainNet
DomainNet
