SummaryMixing: A Linear-Complexity Alternative to Self-Attention for Speech Recognition and Understanding
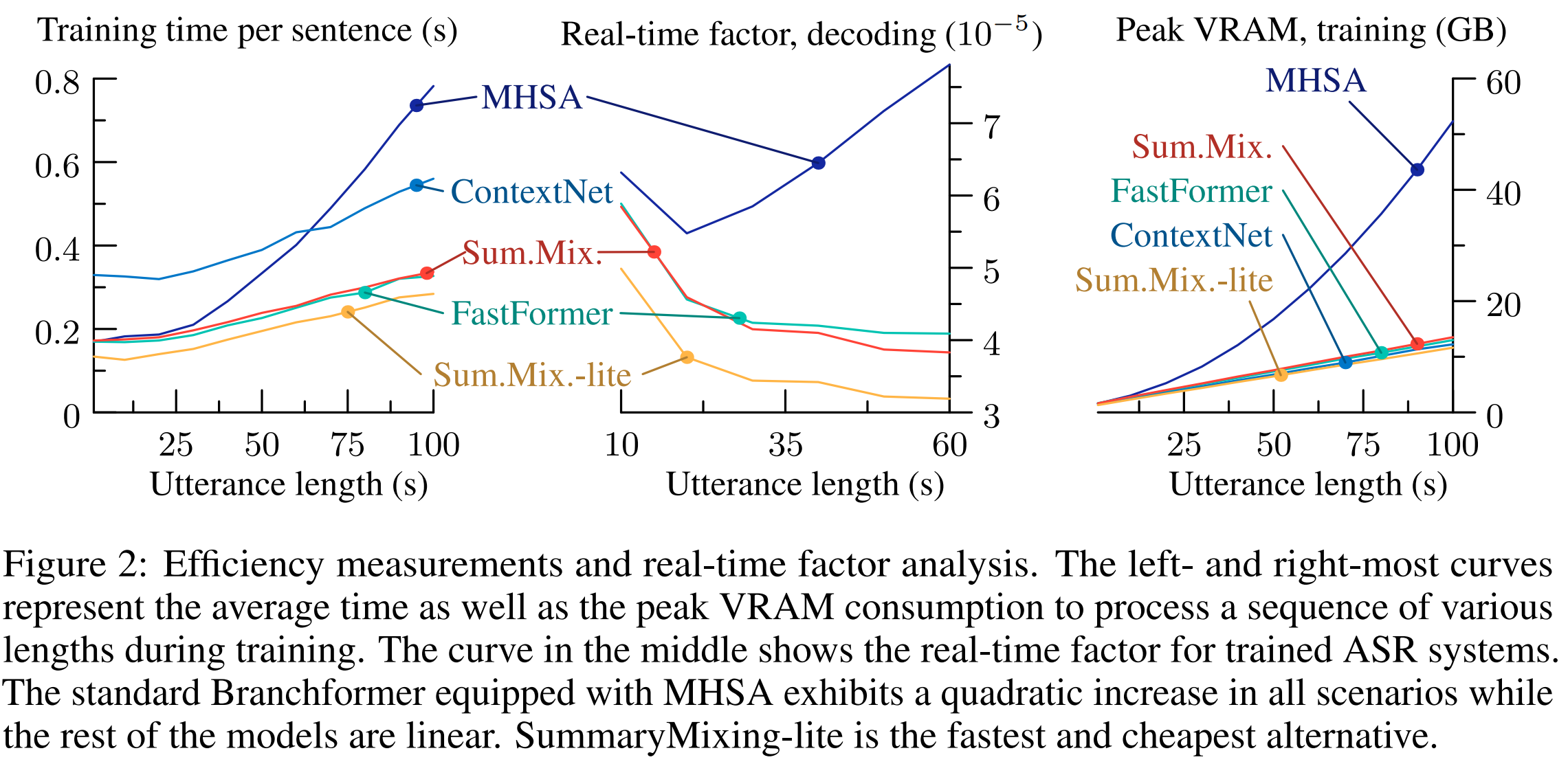
Modern speech processing systems rely on self-attention. Unfortunately, token mixing with self-attention takes quadratic time in the length of the speech utterance, slowing down inference as well as training and increasing memory consumption. Cheaper alternatives to self-attention for ASR have been developed, but they fail to consistently reach the same level of accuracy. This paper, therefore, proposes a novel linear-time alternative to self-attention. It summarises an utterance with the mean over vectors for all time steps. This single summary is then combined with time-specific information. We call this method "SummaryMixing". Introducing SummaryMixing in state-of-the-art ASR models makes it feasible to preserve or exceed previous speech recognition performance while lowering the training and inference times by up to 28$\%$ and reducing the memory budget by a factor of two. The benefits of SummaryMixing can also be generalized to other speech-processing tasks, such as speech understanding.
PDF Abstract


 LibriSpeech
LibriSpeech
 AISHELL-1
AISHELL-1
