Structure-CLIP: Towards Scene Graph Knowledge to Enhance Multi-modal Structured Representations
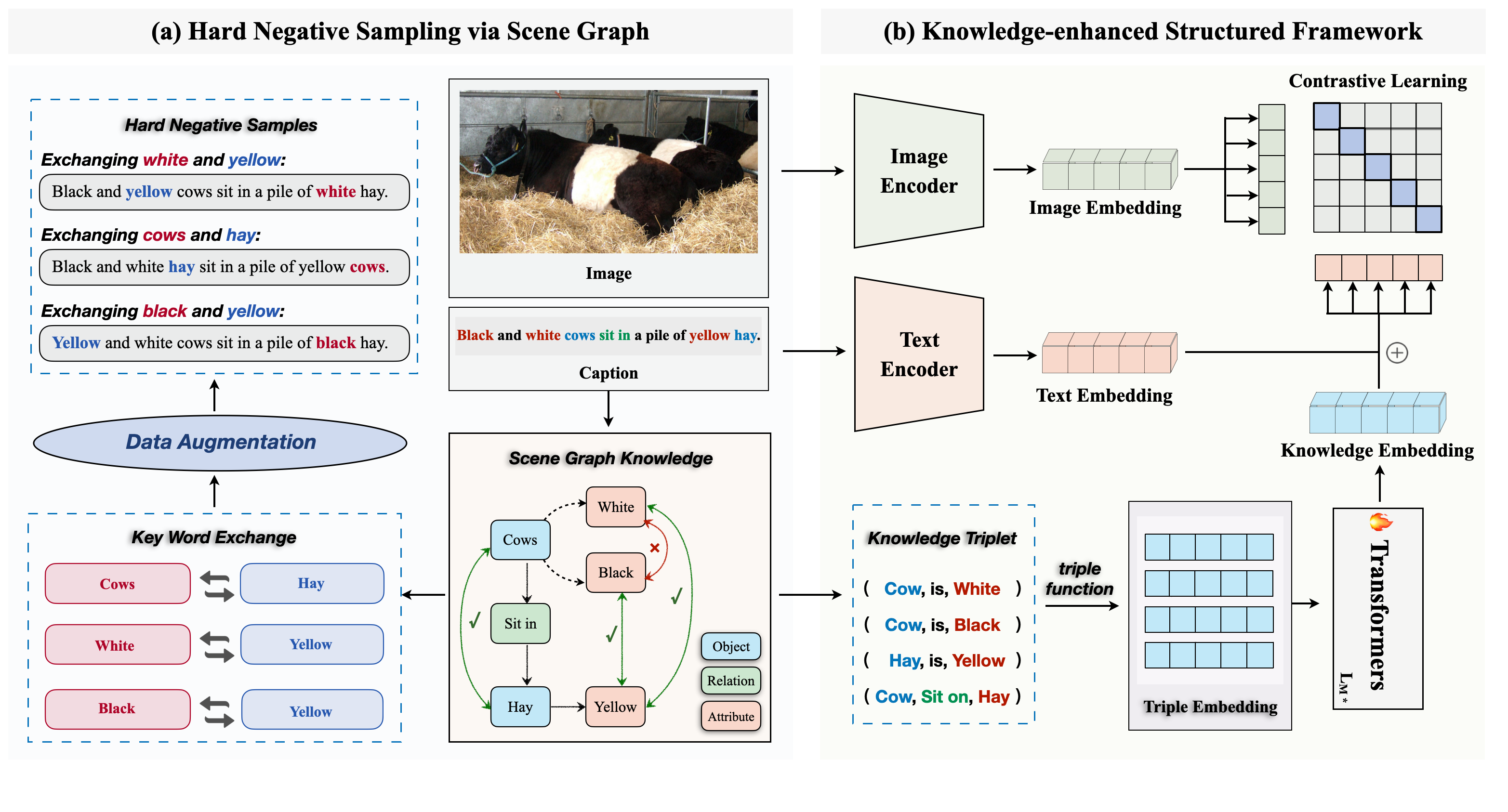
Large-scale vision-language pre-training has achieved significant performance in multi-modal understanding and generation tasks. However, existing methods often perform poorly on image-text matching tasks that require structured representations, i.e., representations of objects, attributes, and relations. As illustrated in Fig.~reffig:case (a), the models cannot make a distinction between ``An astronaut rides a horse" and ``A horse rides an astronaut". This is because they fail to fully leverage structured knowledge when learning representations in multi-modal scenarios. In this paper, we present an end-to-end framework Structure-CLIP, which integrates Scene Graph Knowledge (SGK) to enhance multi-modal structured representations. Firstly, we use scene graphs to guide the construction of semantic negative examples, which results in an increased emphasis on learning structured representations. Moreover, a Knowledge-Enhance Encoder (KEE) is proposed to leverage SGK as input to further enhance structured representations. To verify the effectiveness of the proposed framework, we pre-train our model with the aforementioned approaches and conduct experiments on downstream tasks. Experimental results demonstrate that Structure-CLIP achieves state-of-the-art (SOTA) performance on VG-Attribution and VG-Relation datasets, with 12.5% and 4.1% ahead of the multi-modal SOTA model respectively. Meanwhile, the results on MSCOCO indicate that Structure-CLIP significantly enhances the structured representations while maintaining the ability of general representations. Our code is available at https://github.com/zjukg/Structure-CLIP.
PDF Abstract

 MS COCO
MS COCO
