Stochastic Hyperparameter Optimization through Hypernetworks
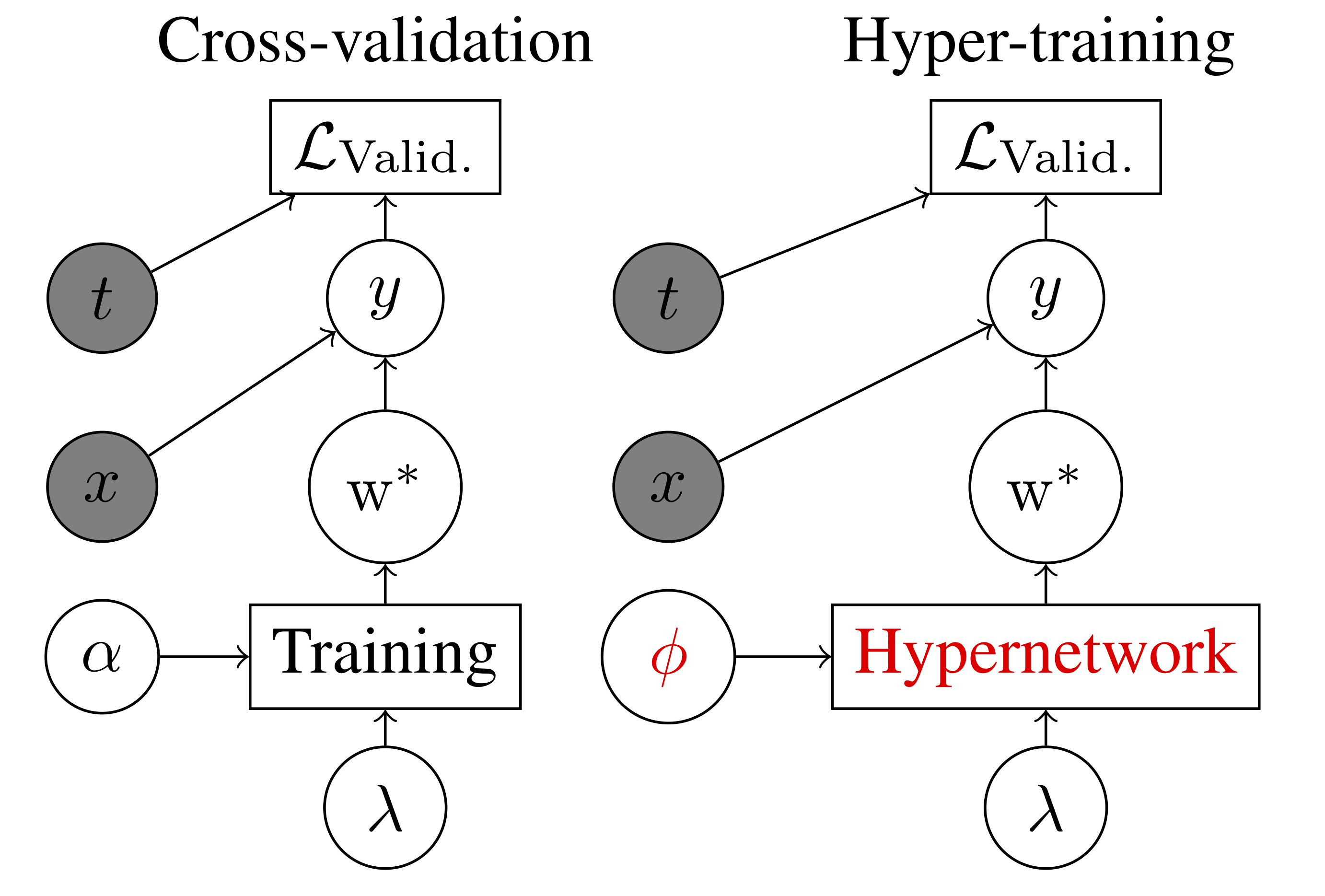
Machine learning models are often tuned by nesting optimization of model weights inside the optimization of hyperparameters. We give a method to collapse this nested optimization into joint stochastic optimization of weights and hyperparameters. Our process trains a neural network to output approximately optimal weights as a function of hyperparameters. We show that our technique converges to locally optimal weights and hyperparameters for sufficiently large hypernetworks. We compare this method to standard hyperparameter optimization strategies and demonstrate its effectiveness for tuning thousands of hyperparameters.
PDF Abstract ICLR 2018 PDF ICLR 2018 AbstractCode

Datasets
Add Datasets
introduced or used in this paper
Results from the Paper
Submit
results from this paper
to get state-of-the-art GitHub badges and help the
community compare results to other papers.
