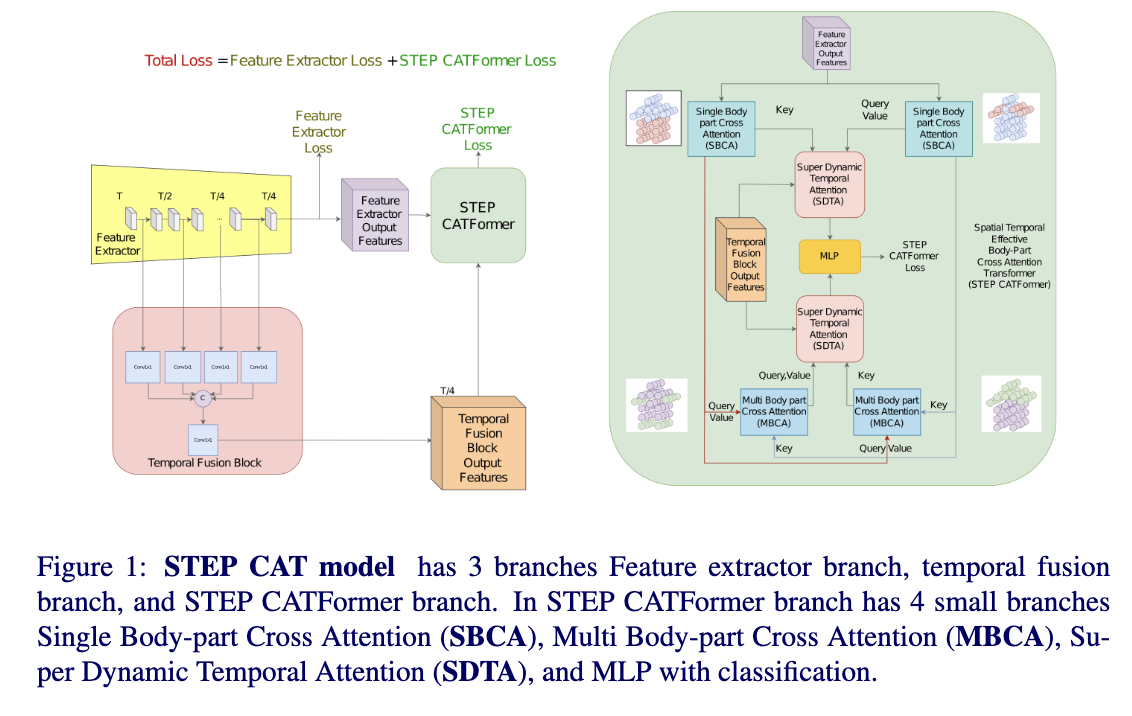
STEP CATFormer: Spatial-Temporal Effective Body-Part Cross Attention Transformer for Skeleton-based Action Recognition
Graph convolutional networks (GCNs) have been widely used and achieved remarkable results in skeleton-based action recognition. We think the key to skeleton-based action recognition is a skeleton hanging in frames, so we focus on how the Graph Convolutional Convolution networks learn different topologies and effectively aggregate joint features in the global temporal and local temporal. In this work, we propose three Channel-wise Tolopogy Graph Convolution based on Channel-wise Topology Refinement Graph Convolution (CTR-GCN). Combining CTR-GCN with two joint cross-attention modules can capture the upper-lower body part and hand-foot relationship skeleton features. After that, to capture features of human skeletons changing in frames we design the Temporal Attention Transformers to extract skeletons effectively. The Temporal Attention Transformers can learn the temporal features of human skeleton sequences. Finally, we fuse the temporal features output scale with MLP and classification. We develop a powerful graph convolutional network named Spatial Temporal Effective Body-part Cross Attention Transformer which notably high-performance on the NTU RGB+D, NTU RGB+D 120 datasets. Our code and models are available at https://github.com/maclong01/STEP-CATFormer
PDF Abstract


Datasets
 NTU RGB+D
NTU RGB+D
 NTU RGB+D 120
NTU RGB+D 120
Results from the Paper
 Ranked #5 on
Skeleton Based Action Recognition
on NTU RGB+D 120
(using extra training data)
Ranked #5 on
Skeleton Based Action Recognition
on NTU RGB+D 120
(using extra training data)
