SRFormer: Permuted Self-Attention for Single Image Super-Resolution
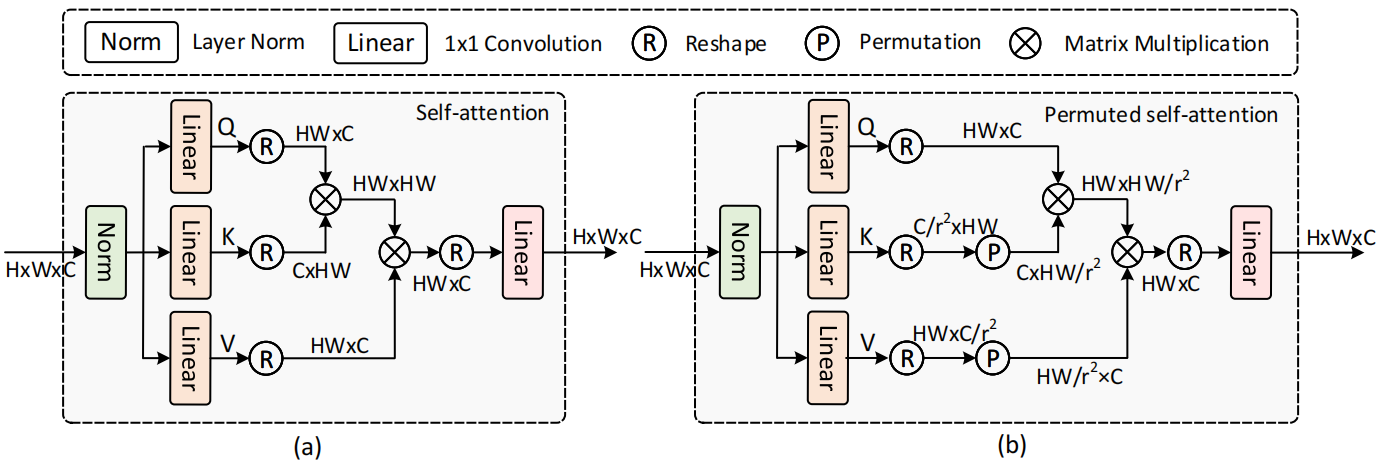
Previous works have shown that increasing the window size for Transformer-based image super-resolution models (e.g., SwinIR) can significantly improve the model performance but the computation overhead is also considerable. In this paper, we present SRFormer, a simple but novel method that can enjoy the benefit of large window self-attention but introduces even less computational burden. The core of our SRFormer is the permuted self-attention (PSA), which strikes an appropriate balance between the channel and spatial information for self-attention. Our PSA is simple and can be easily applied to existing super-resolution networks based on window self-attention. Without any bells and whistles, we show that our SRFormer achieves a 33.86dB PSNR score on the Urban100 dataset, which is 0.46dB higher than that of SwinIR but uses fewer parameters and computations. We hope our simple and effective approach can serve as a useful tool for future research in super-resolution model design.
PDF Abstract ICCV 2023 PDF ICCV 2023 Abstract


 Urban100
Urban100
 Set14
Set14
 Set5
Set5
 Manga109
Manga109
