SpeechLM: Enhanced Speech Pre-Training with Unpaired Textual Data
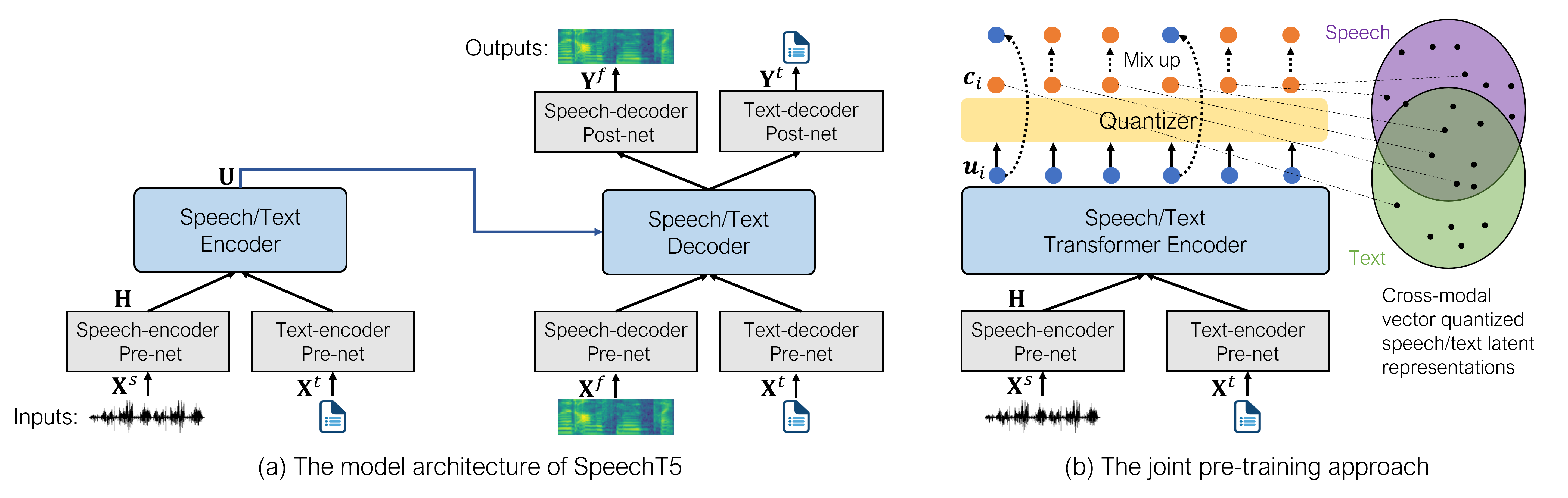
How to boost speech pre-training with textual data is an unsolved problem due to the fact that speech and text are very different modalities with distinct characteristics. In this paper, we propose a cross-modal Speech and Language Model (SpeechLM) to explicitly align speech and text pre-training with a pre-defined unified discrete representation. Specifically, we introduce two alternative discrete tokenizers to bridge the speech and text modalities, including phoneme-unit and hidden-unit tokenizers, which can be trained using a small amount of paired speech-text data. Based on the trained tokenizers, we convert the unlabeled speech and text data into tokens of phoneme units or hidden units. The pre-training objective is designed to unify the speech and the text into the same discrete semantic space with a unified Transformer network. We evaluate SpeechLM on various spoken language processing tasks including speech recognition, speech translation, and universal representation evaluation framework SUPERB, demonstrating significant improvements on content-related tasks. Code and models are available at https://aka.ms/SpeechLM.
PDF Abstract



 LibriSpeech
LibriSpeech
