Speech Enhancement with Score-Based Generative Models in the Complex STFT Domain
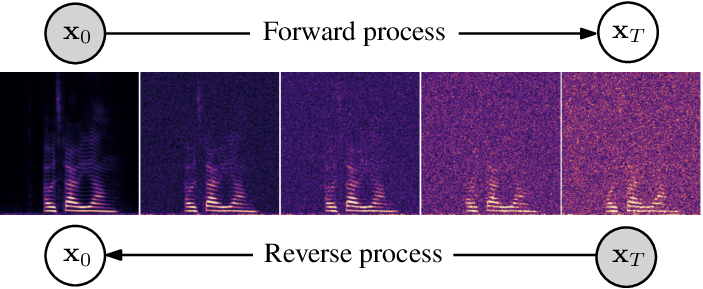
Score-based generative models (SGMs) have recently shown impressive results for difficult generative tasks such as the unconditional and conditional generation of natural images and audio signals. In this work, we extend these models to the complex short-time Fourier transform (STFT) domain, proposing a novel training task for speech enhancement using a complex-valued deep neural network. We derive this training task within the formalism of stochastic differential equations (SDEs), thereby enabling the use of predictor-corrector samplers. We provide alternative formulations inspired by previous publications on using generative diffusion models for speech enhancement, avoiding the need for any prior assumptions on the noise distribution and making the training task purely generative which, as we show, results in improved enhancement performance.
PDF Abstract

