Speak Foreign Languages with Your Own Voice: Cross-Lingual Neural Codec Language Modeling
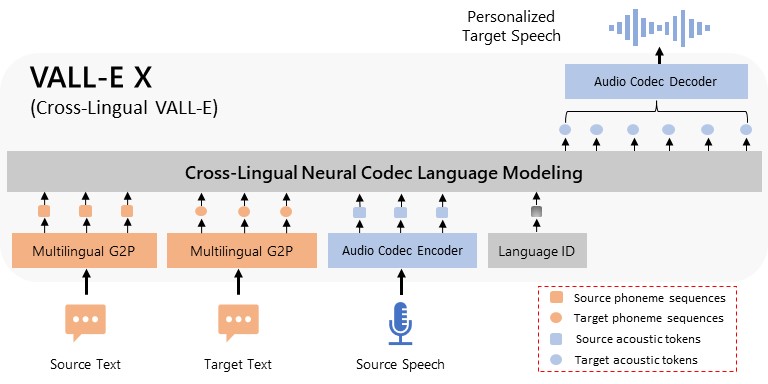
We propose a cross-lingual neural codec language model, VALL-E X, for cross-lingual speech synthesis. Specifically, we extend VALL-E and train a multi-lingual conditional codec language model to predict the acoustic token sequences of the target language speech by using both the source language speech and the target language text as prompts. VALL-E X inherits strong in-context learning capabilities and can be applied for zero-shot cross-lingual text-to-speech synthesis and zero-shot speech-to-speech translation tasks. Experimental results show that it can generate high-quality speech in the target language via just one speech utterance in the source language as a prompt while preserving the unseen speaker's voice, emotion, and acoustic environment. Moreover, VALL-E X effectively alleviates the foreign accent problems, which can be controlled by a language ID. Audio samples are available at \url{https://aka.ms/vallex}.
PDF Abstract Colab
Colab
 Spaces
Spaces




 LibriSpeech
LibriSpeech
