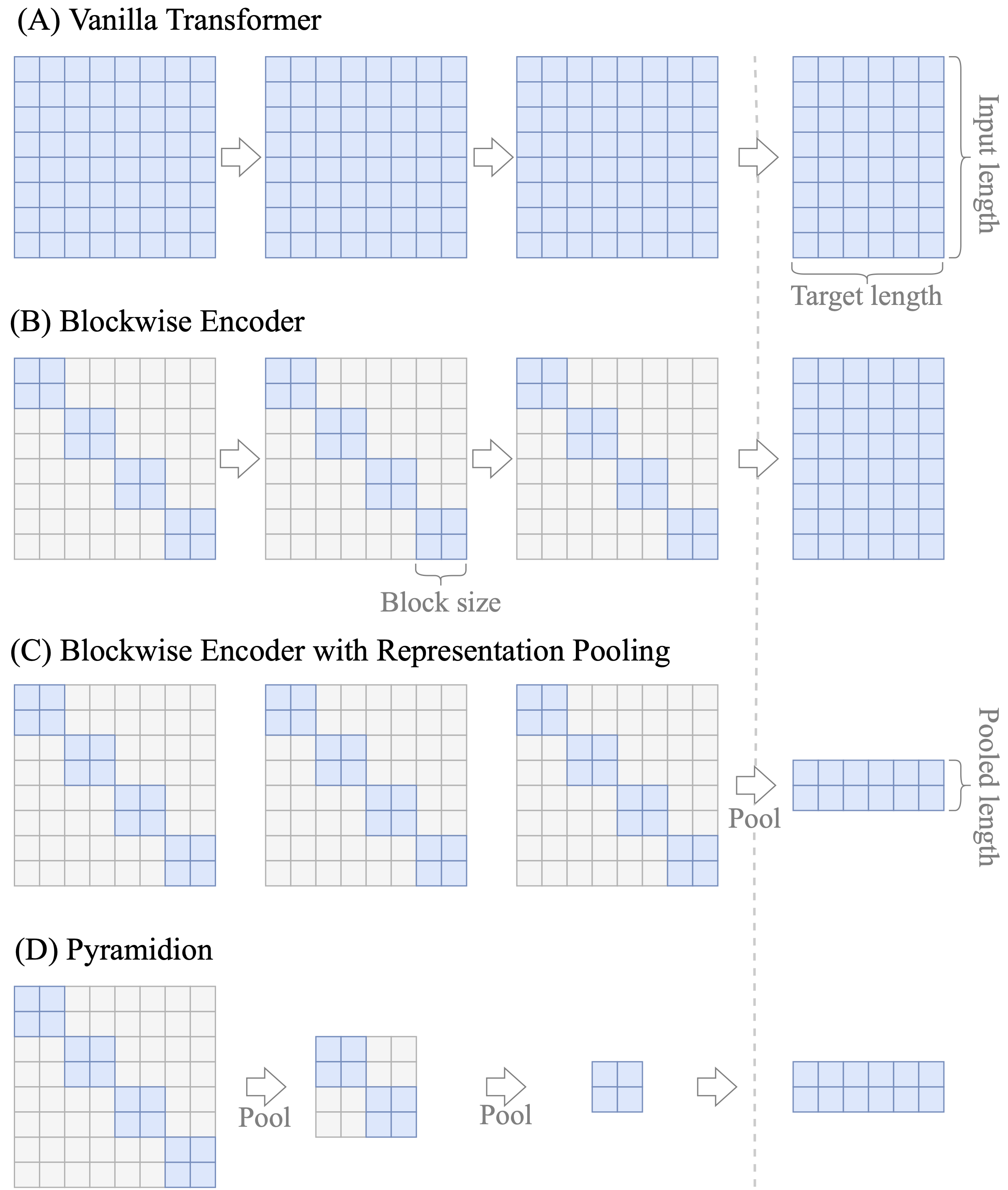
Sparsifying Transformer Models with Trainable Representation Pooling
We propose a novel method to sparsify attention in the Transformer model by learning to select the most-informative token representations during the training process, thus focusing on the task-specific parts of an input. A reduction of quadratic time and memory complexity to sublinear was achieved due to a robust trainable top-$k$ operator. Our experiments on a challenging long document summarization task show that even our simple baseline performs comparably to the current SOTA, and with trainable pooling, we can retain its top quality, while being $1.8\times$ faster during training, $4.5\times$ faster during inference, and up to $13\times$ more computationally efficient in the decoder.
PDF Abstract ACL 2022 PDF ACL 2022 AbstractCode



Datasets
Results from the Paper

Methods
Absolute Position Encodings •
Adam •
Attention Dropout •
BPE •
Cosine Annealing •
Dense Connections •
Dropout •
GELU •
Label Smoothing •
Layer Normalization •
Linear Layer •
Linear Warmup With Cosine Annealing •
Multi-Head Attention •
Position-Wise Feed-Forward Layer •
Residual Connection •
Scaled Dot-Product Attention •
Softmax •
Sparse Transformer •
Transformer •
Weight Decay
