Sparse is Enough in Fine-tuning Pre-trained Large Language Model
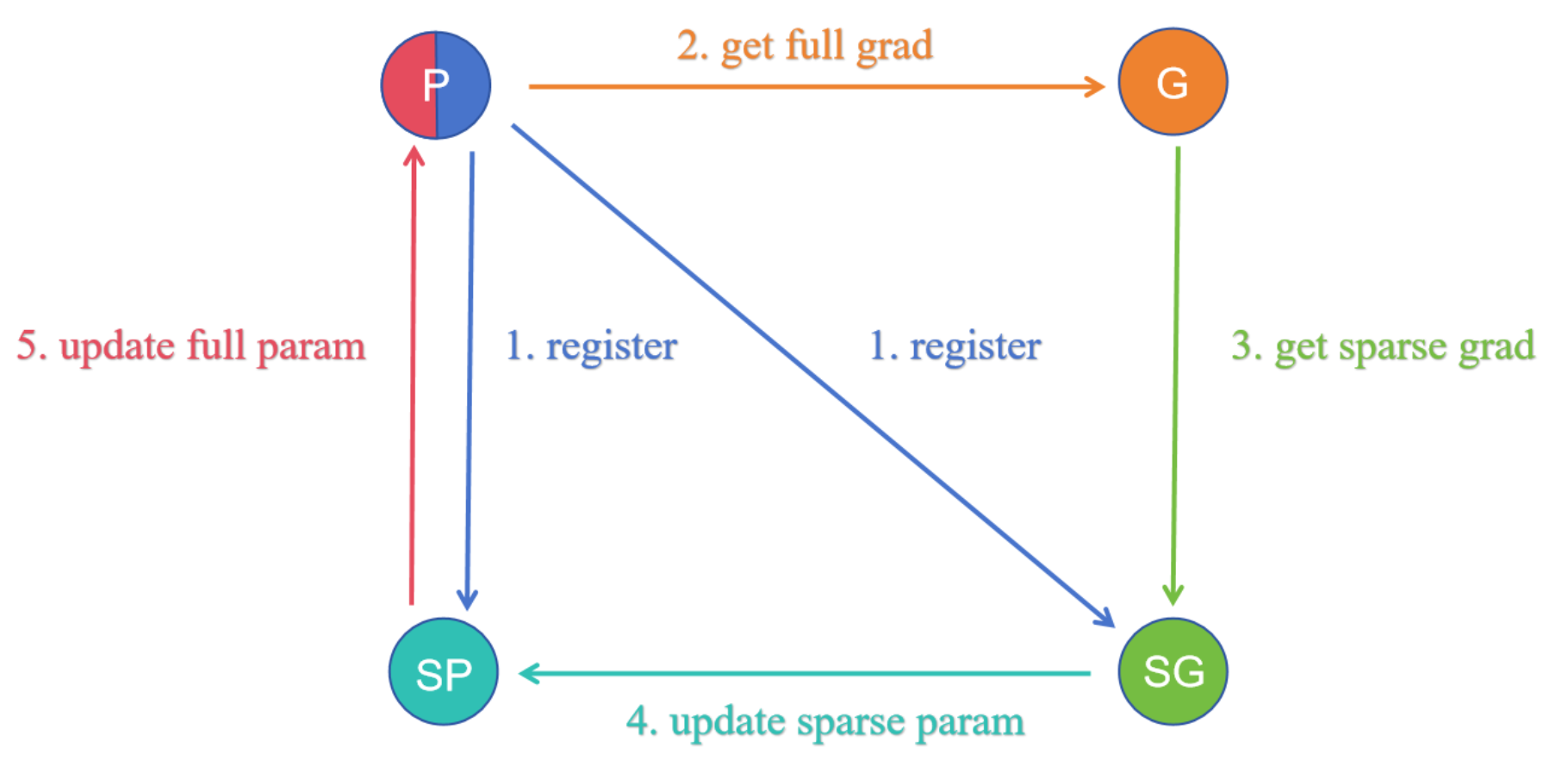
With the prevalence of pre-training-fine-tuning paradigm, how to efficiently adapt the pre-trained model to the downstream tasks has been an intriguing issue. Parameter-Efficient Fine-Tuning (PEFT) methods have been proposed for low-cost adaptation, including Adapters, Bia-only, and the recently widely used Low-Rank Adaptation. Although these methods have demonstrated their effectiveness to some extent and have been widely applied, the underlying principles are still unclear. In this paper, we reveal the transition of loss landscape in the downstream domain from random initialization to pre-trained initialization, that is, from low-amplitude oscillation to high-amplitude oscillation. The parameter gradients exhibit a property akin to sparsity, where a small fraction of components dominate the total gradient norm, for instance, 1% of the components account for 99% of the gradient. This property ensures that the pre-trained model can easily find a flat minimizer which guarantees the model's ability to generalize even with a low number of trainable parameters. Based on this, we propose a gradient-based sparse fine-tuning algorithm, named Sparse Increment Fine-Tuning (SIFT), and validate its effectiveness on a range of tasks including the GLUE Benchmark and Instruction-tuning. The code is accessible at https://github.com/song-wx/SIFT/.
PDF Abstract


 GLUE
GLUE
 MMLU
MMLU
