Sparse and Imperceivable Adversarial Attacks
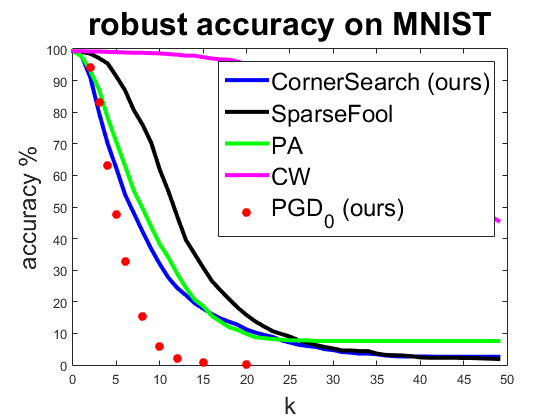
Neural networks have been proven to be vulnerable to a variety of adversarial attacks. From a safety perspective, highly sparse adversarial attacks are particularly dangerous. On the other hand the pixelwise perturbations of sparse attacks are typically large and thus can be potentially detected. We propose a new black-box technique to craft adversarial examples aiming at minimizing $l_0$-distance to the original image. Extensive experiments show that our attack is better or competitive to the state of the art. Moreover, we can integrate additional bounds on the componentwise perturbation. Allowing pixels to change only in region of high variation and avoiding changes along axis-aligned edges makes our adversarial examples almost non-perceivable. Moreover, we adapt the Projected Gradient Descent attack to the $l_0$-norm integrating componentwise constraints. This allows us to do adversarial training to enhance the robustness of classifiers against sparse and imperceivable adversarial manipulations.
PDF Abstract ICCV 2019 PDF ICCV 2019 Abstract
 ImageNet
ImageNet
