Source Prompt Disentangled Inversion for Boosting Image Editability with Diffusion Models
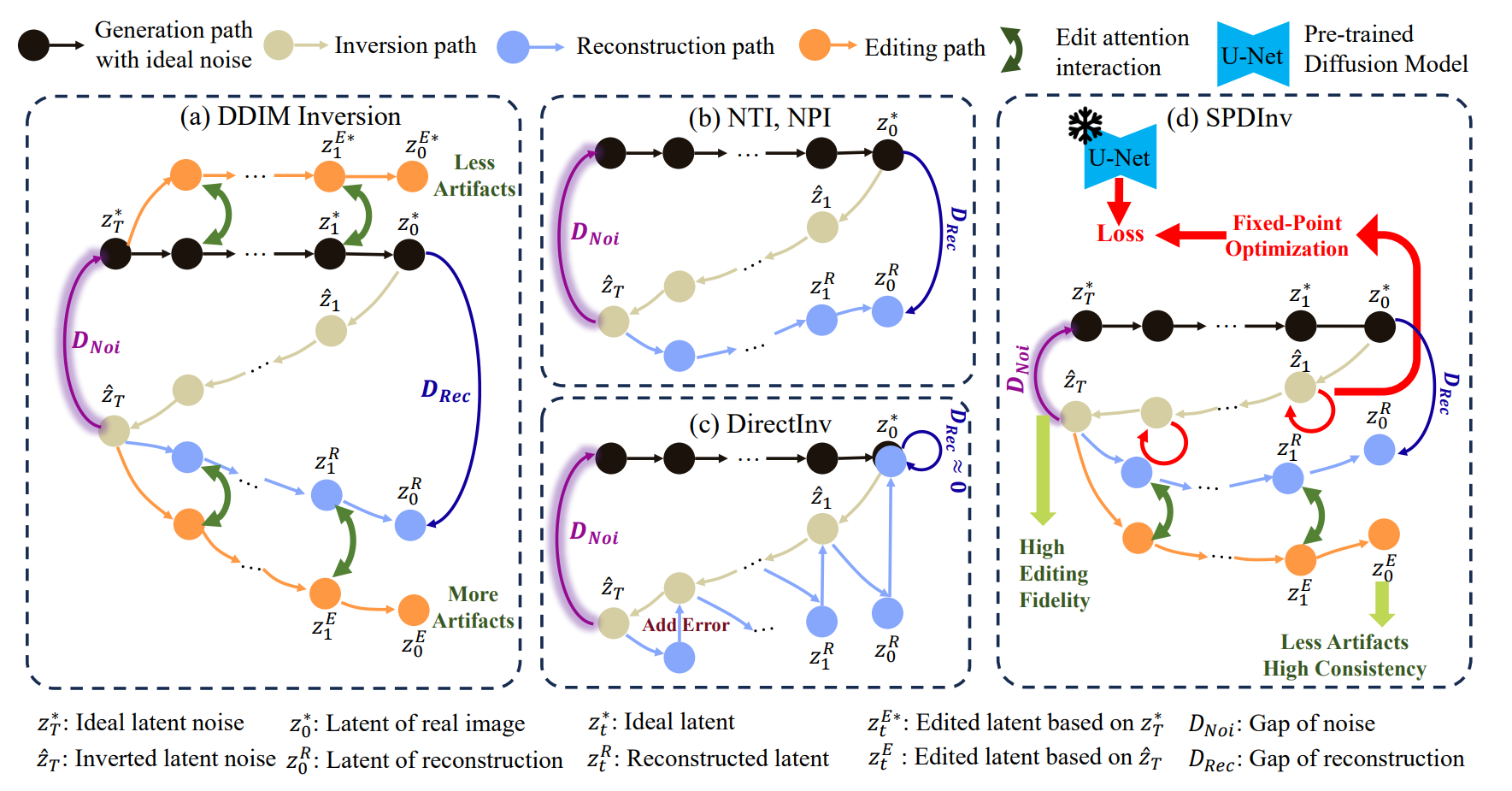
Text-driven diffusion models have significantly advanced the image editing performance by using text prompts as inputs. One crucial step in text-driven image editing is to invert the original image into a latent noise code conditioned on the source prompt. While previous methods have achieved promising results by refactoring the image synthesizing process, the inverted latent noise code is tightly coupled with the source prompt, limiting the image editability by target text prompts. To address this issue, we propose a novel method called Source Prompt Disentangled Inversion (SPDInv), which aims at reducing the impact of source prompt, thereby enhancing the text-driven image editing performance by employing diffusion models. To make the inverted noise code be independent of the given source prompt as much as possible, we indicate that the iterative inversion process should satisfy a fixed-point constraint. Consequently, we transform the inversion problem into a searching problem to find the fixed-point solution, and utilize the pre-trained diffusion models to facilitate the searching process. The experimental results show that our proposed SPDInv method can effectively mitigate the conflicts between the target editing prompt and the source prompt, leading to a significant decrease in editing artifacts. In addition to text-driven image editing, with SPDInv we can easily adapt customized image generation models to localized editing tasks and produce promising performance. The source code are available at https://github.com/leeruibin/SPDInv.
PDF Abstract

 MS COCO
MS COCO
