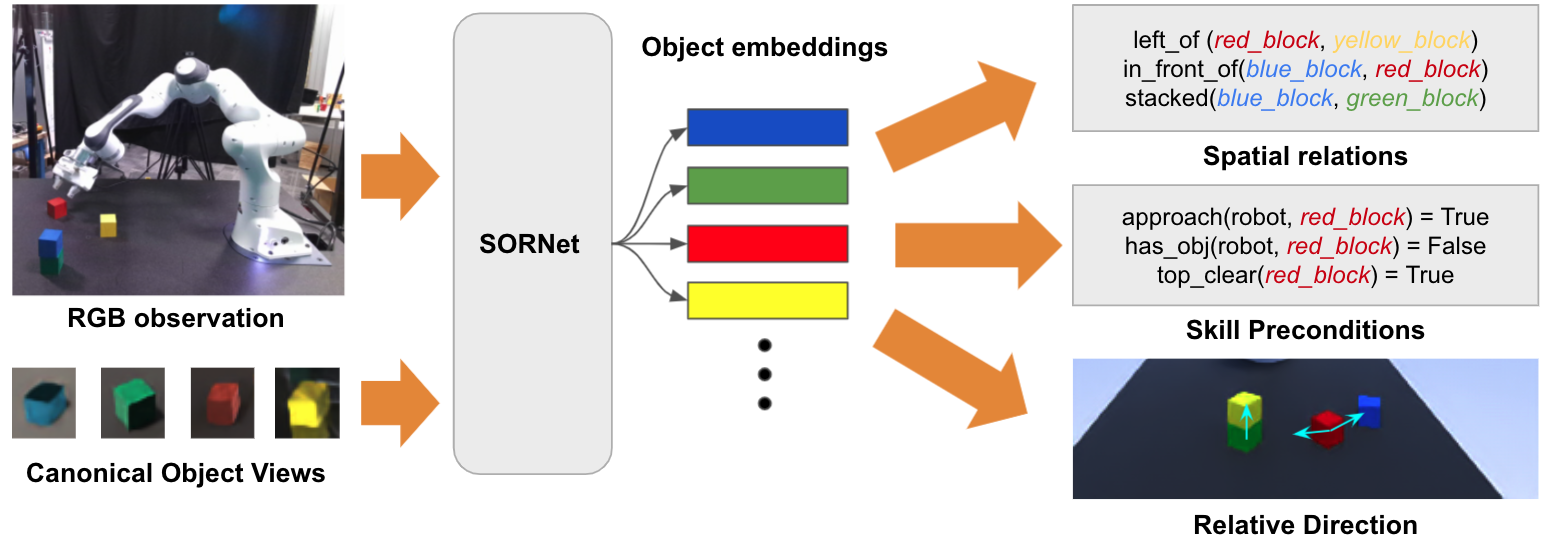
SORNet: Spatial Object-Centric Representations for Sequential Manipulation
Sequential manipulation tasks require a robot to perceive the state of an environment and plan a sequence of actions leading to a desired goal state. In such tasks, the ability to reason about spatial relations among object entities from raw sensor inputs is crucial in order to determine when a task has been completed and which actions can be executed. In this work, we propose SORNet (Spatial Object-Centric Representation Network), a framework for learning object-centric representations from RGB images conditioned on a set of object queries, represented as image patches called canonical object views. With only a single canonical view per object and no annotation, SORNet generalizes zero-shot to object entities whose shape and texture are both unseen during training. We evaluate SORNet on various spatial reasoning tasks such as spatial relation classification and relative direction regression in complex tabletop manipulation scenarios and show that SORNet significantly outperforms baselines including state-of-the-art representation learning techniques. We also demonstrate the application of the representation learned by SORNet on visual-servoing and task planning for sequential manipulation on a real robot.
PDF Abstract


 ShapeNet
ShapeNet
 CLEVR
CLEVR
