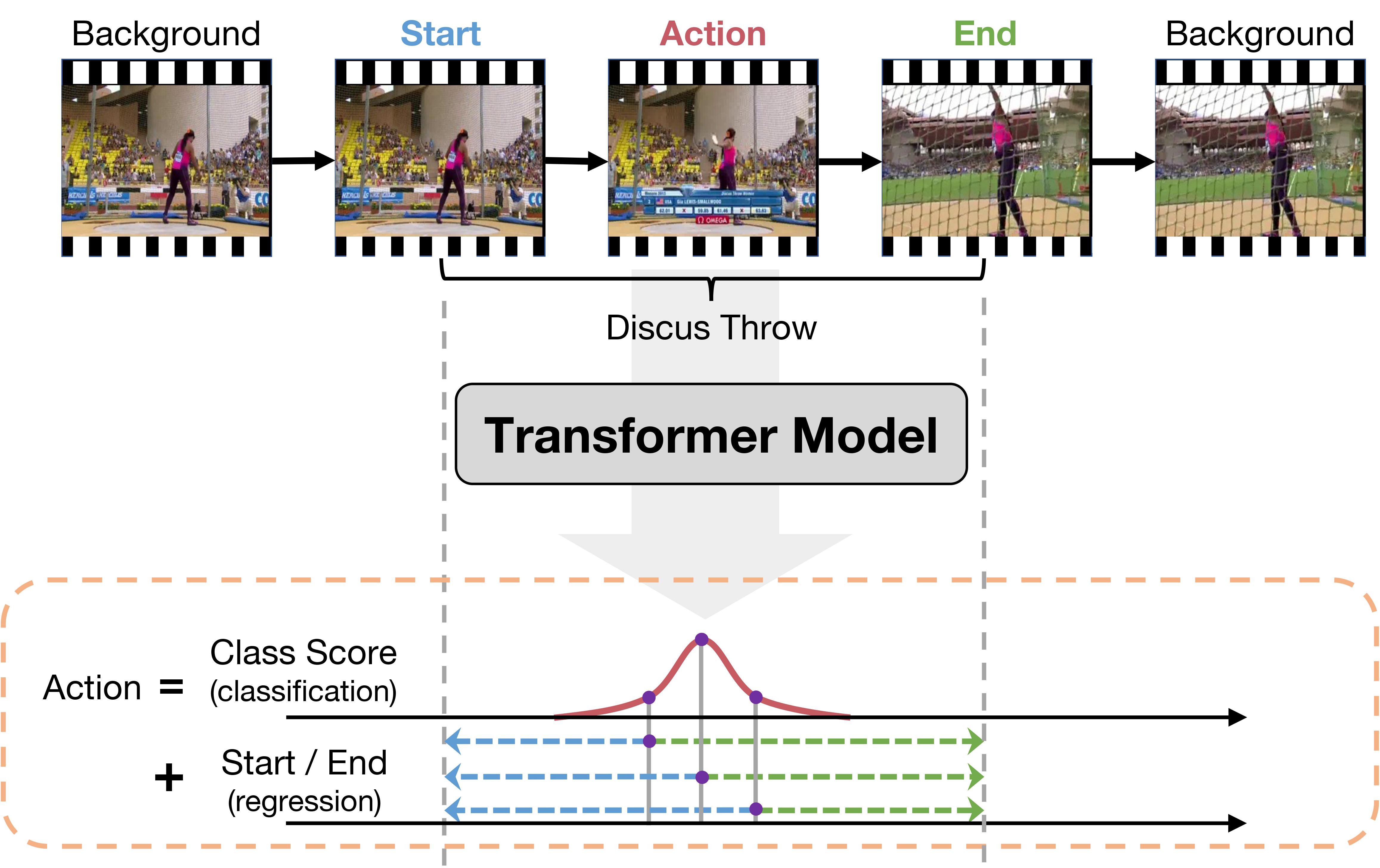
SnAG: Scalable and Accurate Video Grounding
Temporal grounding of text descriptions in videos is a central problem in vision-language learning and video understanding. Existing methods often prioritize accuracy over scalability -- they have been optimized for grounding only a few text queries within short videos, and fail to scale up to long videos with hundreds of queries. In this paper, we study the effect of cross-modal fusion on the scalability of video grounding models. Our analysis establishes late fusion as a more cost-effective fusion scheme for long-form videos with many text queries. Moreover, it leads us to a novel, video-centric sampling scheme for efficient training. Based on these findings, we present SnAG, a simple baseline for scalable and accurate video grounding. Without bells and whistles, SnAG is 43% more accurate and 1.5x faster than CONE, a state of the art for long-form video grounding on the challenging MAD dataset, while achieving highly competitive results on short videos.
PDF Abstract

 Charades
Charades
 ActivityNet Captions
ActivityNet Captions
 Charades-STA
Charades-STA
 MAD
MAD
