Small Language Models Improve Giants by Rewriting Their Outputs
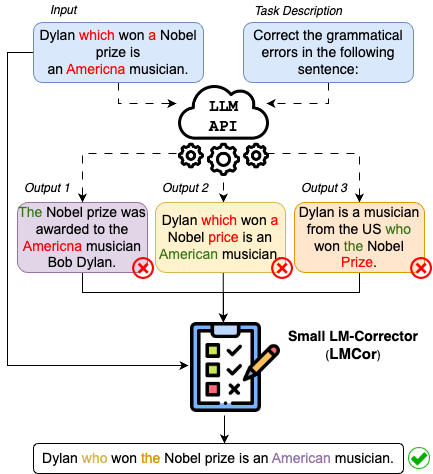
Despite the impressive performance of large language models (LLMs), they often lag behind specialized models in various tasks. LLMs only use a fraction of the existing training data for in-context learning, while task-specific models harness the full dataset for fine-tuning. In this work, we tackle the problem of leveraging training data to improve the performance of LLMs without fine-tuning. Our approach directly targets LLM predictions without requiring access to their weights. We create a pool of candidates from the LLM through few-shot prompting and we employ a compact model, the LM-corrector (LMCor), specifically trained to merge these candidates to produce an enhanced output. Our experiments on four natural language generation tasks demonstrate that even a small LMCor model (250M) substantially improves the few-shot performance of LLMs (62B), matching and even outperforming standard fine-tuning. Furthermore, we illustrate the robustness of LMCor against different prompts, thereby minimizing the need for extensive prompt engineering. Finally, we show that LMCor can be seamlessly integrated with different LLMs at inference, serving as a plug-and-play module to improve their performance.
PDF Abstract



