Motion-driven Visual Tempo Learning for Video-based Action Recognition
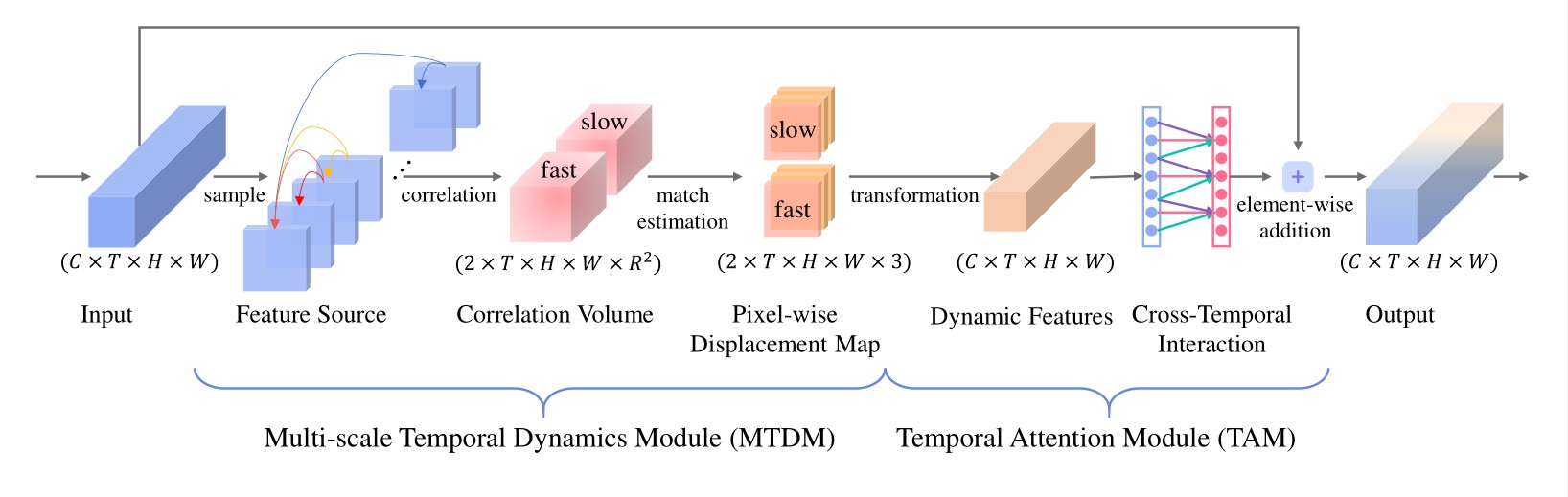
Action visual tempo characterizes the dynamics and the temporal scale of an action, which is helpful to distinguish human actions that share high similarities in visual dynamics and appearance. Previous methods capture the visual tempo either by sampling raw videos with multiple rates, which require a costly multi-layer network to handle each rate, or by hierarchically sampling backbone features, which rely heavily on high-level features that miss fine-grained temporal dynamics. In this work, we propose a Temporal Correlation Module (TCM), which can be easily embedded into the current action recognition backbones in a plug-in-and-play manner, to extract action visual tempo from low-level backbone features at single-layer remarkably. Specifically, our TCM contains two main components: a Multi-scale Temporal Dynamics Module (MTDM) and a Temporal Attention Module (TAM). MTDM applies a correlation operation to learn pixel-wise fine-grained temporal dynamics for both fast-tempo and slow-tempo. TAM adaptively emphasizes expressive features and suppresses inessential ones via analyzing the global information across various tempos. Extensive experiments conducted on several action recognition benchmarks, e.g. Something-Something V1 $\&$ V2, Kinetics-400, UCF-101, and HMDB-51, have demonstrated that the proposed TCM is effective to promote the performance of the existing video-based action recognition models for a large margin. The source code is publicly released at https://github.com/yzfly/TCM.
PDF Abstract TIP 2022 PDF

 UCF101
UCF101
 Kinetics
Kinetics
 HMDB51
HMDB51
 Kinetics 400
Kinetics 400
 Something-Something V2
Something-Something V2
 Something-Something V1
Something-Something V1

