SingleGAN: Image-to-Image Translation by a Single-Generator Network using Multiple Generative Adversarial Learning
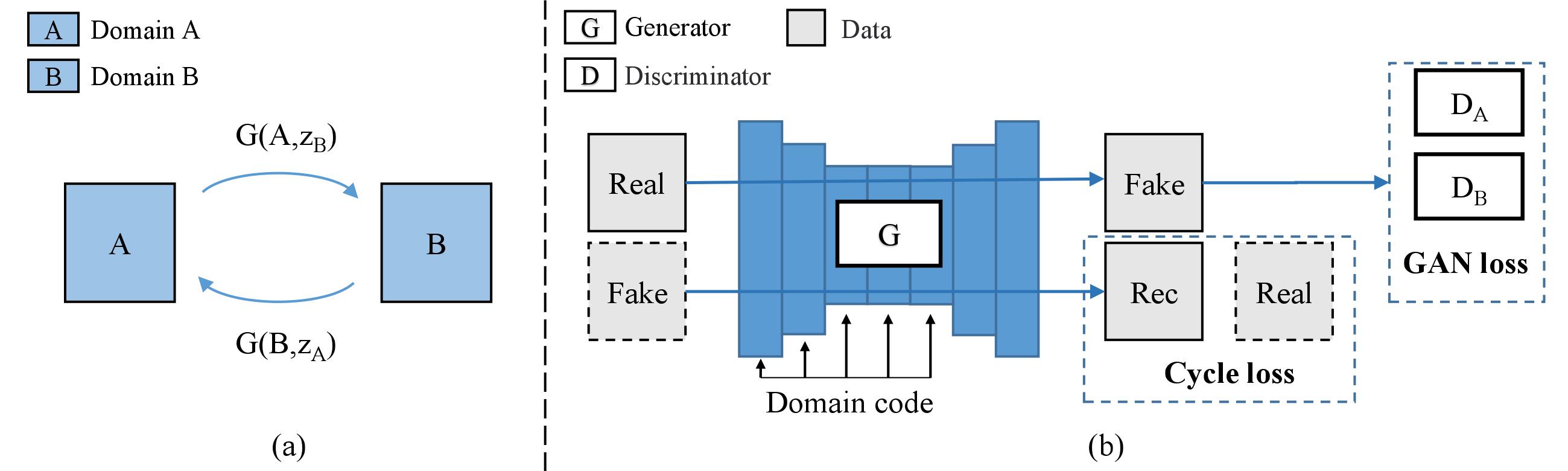
Image translation is a burgeoning field in computer vision where the goal is to learn the mapping between an input image and an output image. However, most recent methods require multiple generators for modeling different domain mappings, which are inefficient and ineffective on some multi-domain image translation tasks. In this paper, we propose a novel method, SingleGAN, to perform multi-domain image-to-image translations with a single generator. We introduce the domain code to explicitly control the different generative tasks and integrate multiple optimization goals to ensure the translation. Experimental results on several unpaired datasets show superior performance of our model in translation between two domains. Besides, we explore variants of SingleGAN for different tasks, including one-to-many domain translation, many-to-many domain translation and one-to-one domain translation with multimodality. The extended experiments show the universality and extensibility of our model.
PDF Abstract


