Single channel voice separation for unknown number of speakers under reverberant and noisy settings
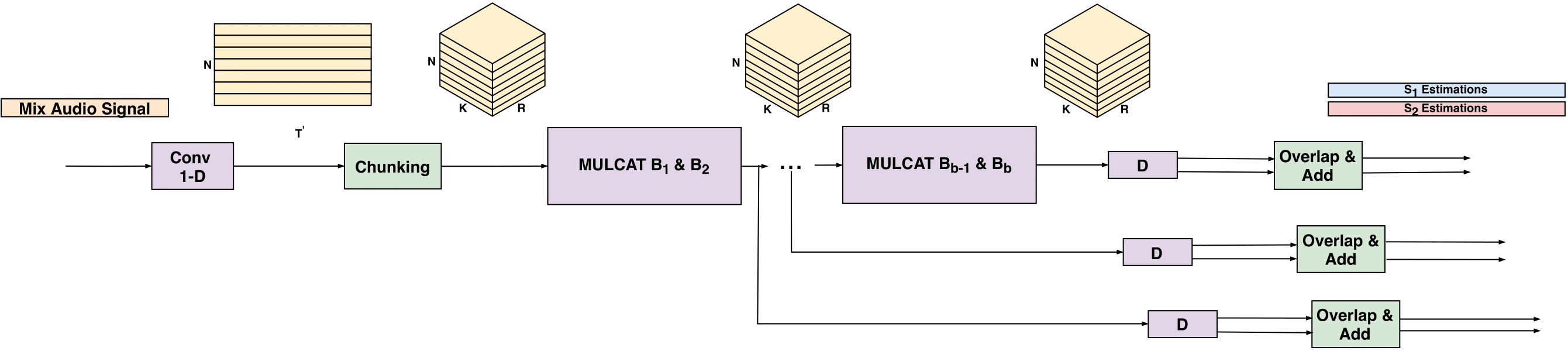
We present a unified network for voice separation of an unknown number of speakers. The proposed approach is composed of several separation heads optimized together with a speaker classification branch. The separation is carried out in the time domain, together with parameter sharing between all separation heads. The classification branch estimates the number of speakers while each head is specialized in separating a different number of speakers. We evaluate the proposed model under both clean and noisy reverberant set-tings. Results suggest that the proposed approach is superior to the baseline model by a significant margin. Additionally, we present a new noisy and reverberant dataset of up to five different speakers speaking simultaneously.
PDF Abstract
 Spaces
Spaces


