Simplifying Transformer Blocks
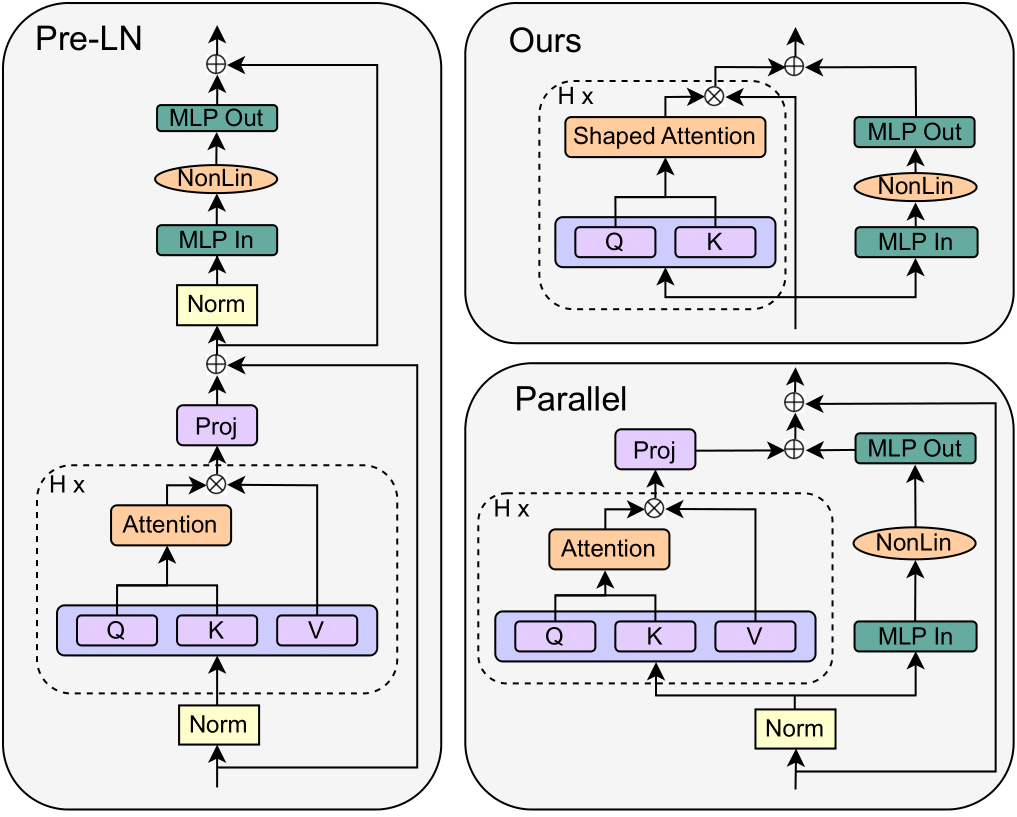
A simple design recipe for deep Transformers is to compose identical building blocks. But standard transformer blocks are far from simple, interweaving attention and MLP sub-blocks with skip connections & normalisation layers in precise arrangements. This complexity leads to brittle architectures, where seemingly minor changes can significantly reduce training speed, or render models untrainable. In this work, we ask to what extent the standard transformer block can be simplified? Combining signal propagation theory and empirical observations, we motivate modifications that allow many block components to be removed with no loss of training speed, including skip connections, projection or value parameters, sequential sub-blocks and normalisation layers. In experiments on both autoregressive decoder-only and BERT encoder-only models, our simplified transformers emulate the per-update training speed and performance of standard transformers, while enjoying 15% faster training throughput, and using 15% fewer parameters.
PDF Abstract Colab
Colab

 GLUE
GLUE
