Composed Fine-Tuning: Freezing Pre-Trained Denoising Autoencoders for Improved Generalization
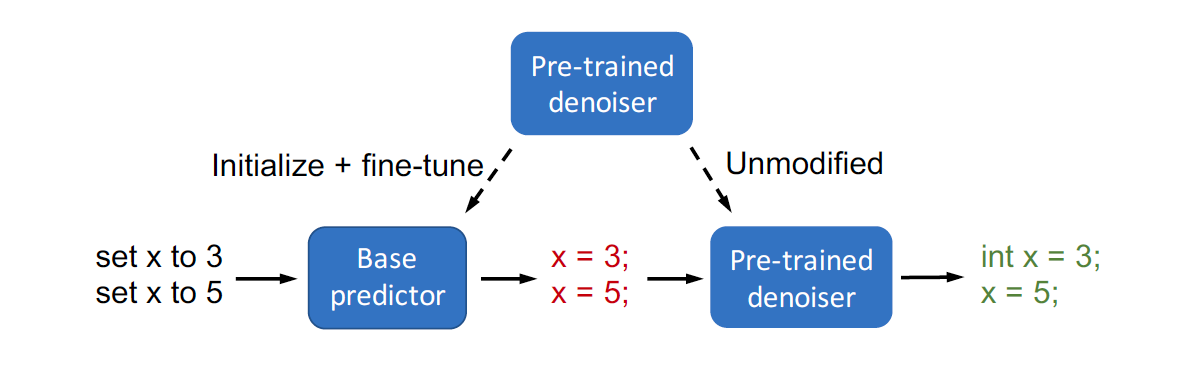
We focus on prediction problems with structured outputs that are subject to output validity constraints, e.g. pseudocode-to-code translation where the code must compile. While labeled input-output pairs are expensive to obtain, "unlabeled" outputs, i.e. outputs without corresponding inputs, are freely available (e.g. code on GitHub) and provide information about output validity. We can capture the output structure by pre-training a denoiser to denoise corrupted versions of unlabeled outputs. We first show that standard fine-tuning after pre-training destroys some of this structure. We then propose composed fine-tuning, which fine-tunes a predictor composed with the pre-trained denoiser, which is frozen to preserve output structure. For two-layer ReLU networks, we prove that composed fine-tuning significantly reduces the complexity of the predictor, thus improving generalization. Empirically, we show that composed fine-tuning improves over standard fine-tuning on two pseudocode-to-code translation datasets (3% and 6% relative). The improvement from composed fine-tuning is magnified on out-of-distribution (OOD) examples (4% and 25% relative).
PDF Abstract



