Siamese-NAS: Using Trained Samples Efficiently to Find Lightweight Neural Architecture by Prior Knowledge
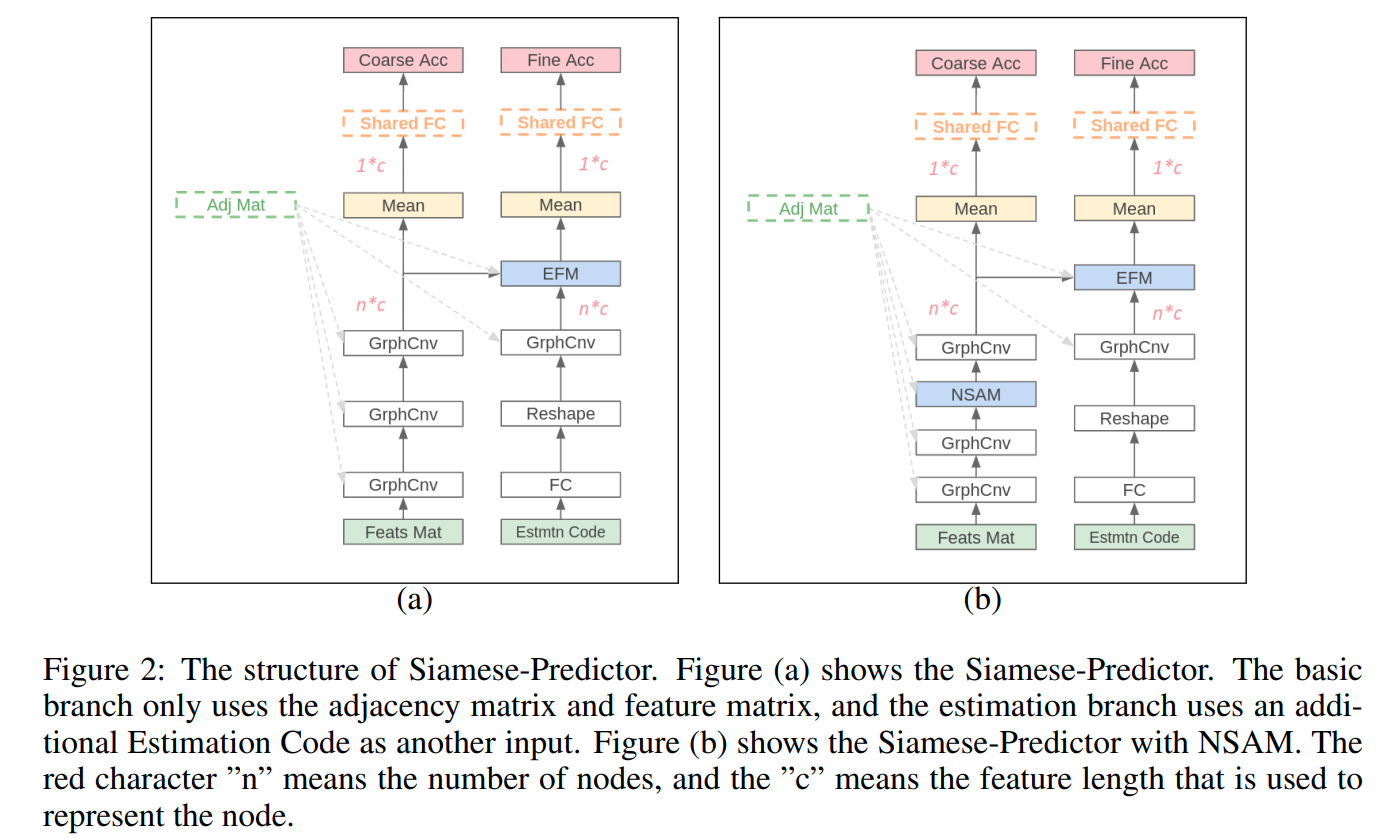
In the past decade, many architectures of convolution neural networks were designed by handcraft, such as Vgg16, ResNet, DenseNet, etc. They all achieve state-of-the-art level on different tasks in their time. However, it still relies on human intuition and experience, and it also takes so much time consumption for trial and error. Neural Architecture Search (NAS) focused on this issue. In recent works, the Neural Predictor has significantly improved with few training architectures as training samples. However, the sampling efficiency is already considerable. In this paper, our proposed Siamese-Predictor is inspired by past works of predictor-based NAS. It is constructed with the proposed Estimation Code, which is the prior knowledge about the training procedure. The proposed Siamese-Predictor gets significant benefits from this idea. This idea causes it to surpass the current SOTA predictor on NASBench-201. In order to explore the impact of the Estimation Code, we analyze the relationship between it and accuracy. We also propose the search space Tiny-NanoBench for lightweight CNN architecture. This well-designed search space is easier to find better architecture with few FLOPs than NASBench-201. In summary, the proposed Siamese-Predictor is a predictor-based NAS. It achieves the SOTA level, especially with limited computation budgets. It applied to the proposed Tiny-NanoBench can just use a few trained samples to find extremely lightweight CNN architecture.
PDF Abstract

 CIFAR-10
CIFAR-10
 CIFAR-100
CIFAR-100
 NAS-Bench-201
NAS-Bench-201
