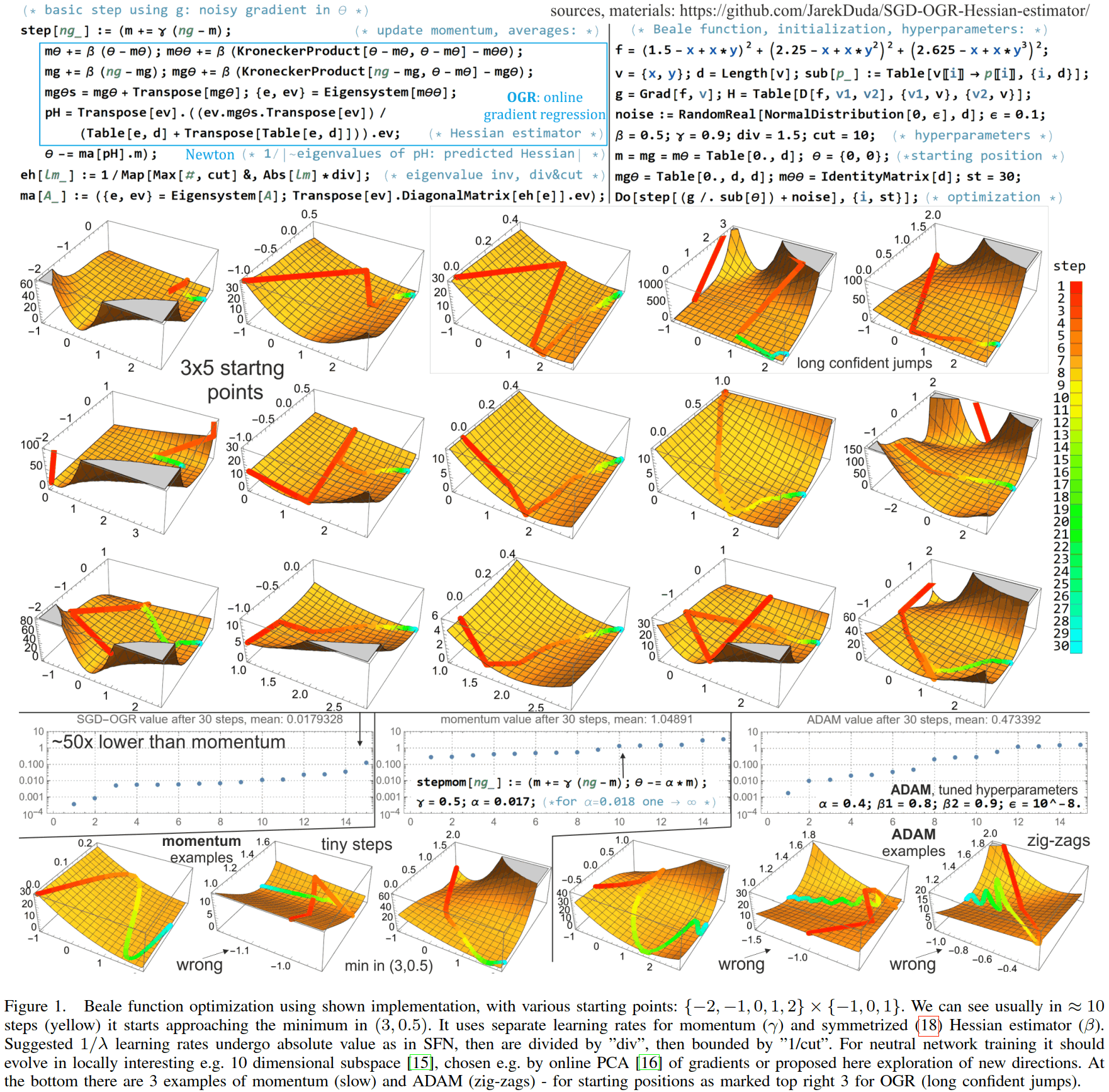
SGD momentum optimizer with step estimation by online parabola model
In stochastic gradient descent, especially for neural network training, there are currently dominating first order methods: not modeling local distance to minimum. This information required for optimal step size is provided by second order methods, however, they have many difficulties, starting with full Hessian having square of dimension number of coefficients. This article proposes a minimal step from successful first order momentum method toward second order: online parabola modelling in just a single direction: normalized $\hat{v}$ from momentum method. It is done by estimating linear trend of gradients $\vec{g}=\nabla F(\vec{\theta})$ in $\hat{v}$ direction: such that $g(\vec{\theta}_\bot+\theta\hat{v})\approx \lambda (\theta -p)$ for $\theta = \vec{\theta}\cdot \hat{v}$, $g= \vec{g}\cdot \hat{v}$, $\vec{\theta}_\bot=\vec{\theta}-\theta\hat{v}$. Using linear regression, $\lambda$, $p$ are MSE estimated by just updating four averages (of $g$, $\theta$, $g\theta$, $\theta^2$) in the considered direction. Exponential moving averages allow here for inexpensive online estimation, weakening contribution of the old gradients. Controlling sign of curvature $\lambda$, we can repel from saddles in contrast to attraction in standard Newton method. In the remaining directions: not considered in second order model, we can simultaneously perform e.g. gradient descent. There is also discussed its learning rate approximation as $\mu=\sigma_\theta / \sigma_g$, allowing e.g. for adaptive SGD - with learning rate separately optimized (2nd order) for each parameter.
PDF Abstract
