SEVEN: Pruning Transformer Model by Reserving Sentinels
Large-scale Transformer models (TM) have demonstrated outstanding performance across various tasks. However, their considerable parameter size restricts their applicability, particularly on mobile devices. Due to the dynamic and intricate nature of gradients on TM compared to Convolutional Neural Networks, commonly used pruning methods tend to retain weights with larger gradient noise. This results in pruned models that are sensitive to sparsity and datasets, exhibiting suboptimal performance. Symbolic Descent (SD) is a general approach for training and fine-tuning TM. In this paper, we attempt to describe the noisy batch gradient sequences on TM through the cumulative process of SD. We utilize this design to dynamically assess the importance scores of weights.SEVEN is introduced by us, which particularly favors weights with consistently high sensitivity, i.e., weights with small gradient noise. These weights are tended to be preserved by SEVEN. Extensive experiments on various TM in natural language, question-answering, and image classification domains are conducted to validate the effectiveness of SEVEN. The results demonstrate significant improvements of SEVEN in multiple pruning scenarios and across different sparsity levels. Additionally, SEVEN exhibits robust performance under various fine-tuning strategies. The code is publicly available at https://github.com/xiaojinying/SEVEN.
PDF Abstract


 CIFAR-10
CIFAR-10
 ImageNet
ImageNet
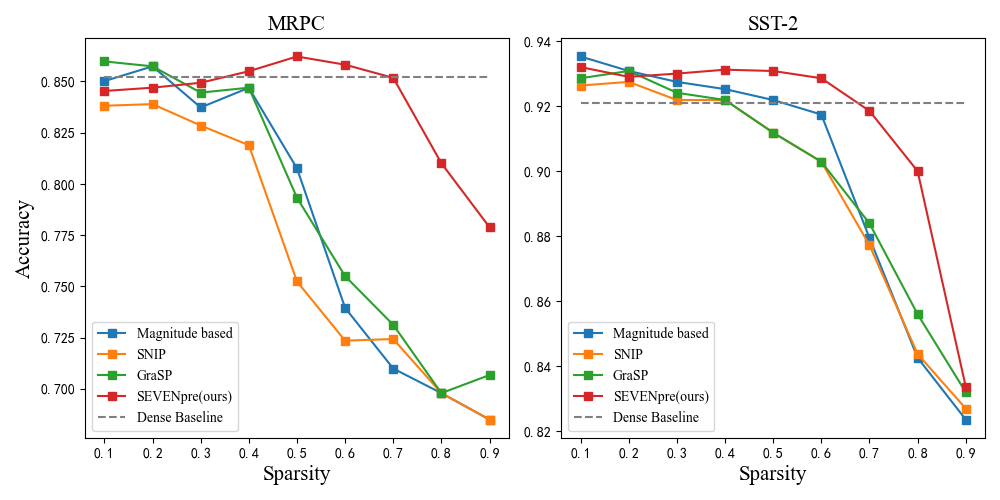
 GLUE
GLUE
 SQuAD
SQuAD
 QNLI
QNLI
