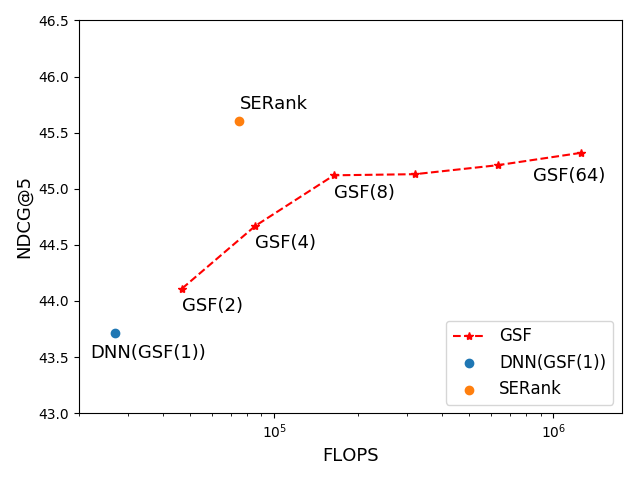
SERank: Optimize Sequencewise Learning to Rank Using Squeeze-and-Excitation Network
Learning-to-rank (LTR) is a set of supervised machine learning algorithms that aim at generating optimal ranking order over a list of items. A lot of ranking models have been studied during the past decades. And most of them treat each query document pair independently during training and inference. Recently, there are a few methods have been proposed which focused on mining information across ranking candidates list for further improvements, such as learning multivariant scoring function or learning contextual embedding. However, these methods usually greatly increase computational cost during online inference, especially when with large candidates size in real-world web search systems. What's more, there are few studies that focus on novel design of model structure for leveraging information across ranking candidates. In this work, we propose an effective and efficient method named as SERank which is a Sequencewise Ranking model by using Squeeze-and-Excitation network to take advantage of cross-document information. Moreover, we examine our proposed methods on several public benchmark datasets, as well as click logs collected from a commercial Question Answering search engine, Zhihu. In addition, we also conduct online A/B testing at Zhihu search engine to further verify the proposed approach. Results on both offline datasets and online A/B testing demonstrate that our method contributes to a significant improvement.
PDF Abstract


