SeqNetVLAD vs PointNetVLAD: Image Sequence vs 3D Point Clouds for Day-Night Place Recognition
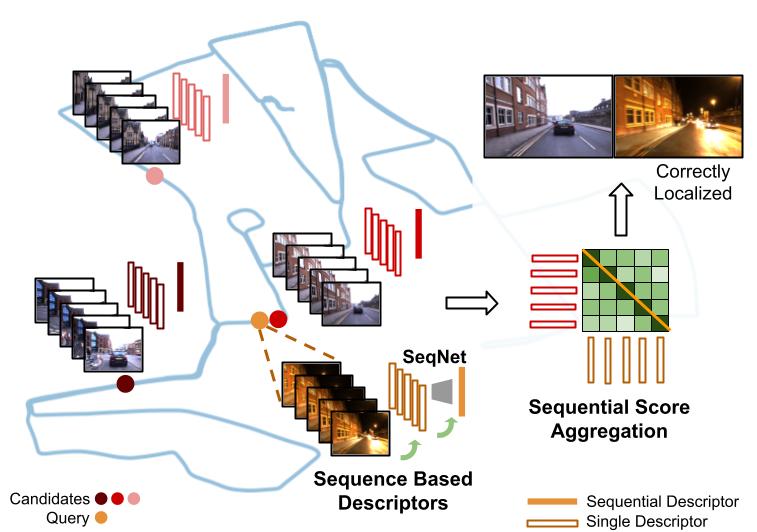
Place Recognition is a crucial capability for mobile robot localization and navigation. Image-based or Visual Place Recognition (VPR) is a challenging problem as scene appearance and camera viewpoint can change significantly when places are revisited. Recent VPR methods based on ``sequential representations'' have shown promising results as compared to traditional sequence score aggregation or single image based techniques. In parallel to these endeavors, 3D point clouds based place recognition is also being explored following the advances in deep learning based point cloud processing. However, a key question remains: is an explicit 3D structure based place representation always superior to an implicit ``spatial'' representation based on sequence of RGB images which can inherently learn scene structure. In this extended abstract, we attempt to compare these two types of methods by considering a similar ``metric span'' to represent places. We compare a 3D point cloud based method (PointNetVLAD) with image sequence based methods (SeqNet and others) and showcase that image sequence based techniques approach, and can even surpass, the performance achieved by point cloud based methods for a given metric span. These performance variations can be attributed to differences in data richness of input sensors as well as data accumulation strategies for a mobile robot. While a perfect apple-to-apple comparison may not be feasible for these two different modalities, the presented comparison takes a step in the direction of answering deeper questions regarding spatial representations, relevant to several applications like Autonomous Driving and Augmented/Virtual Reality. Source code available publicly https://github.com/oravus/seqNet.
PDF Abstract


