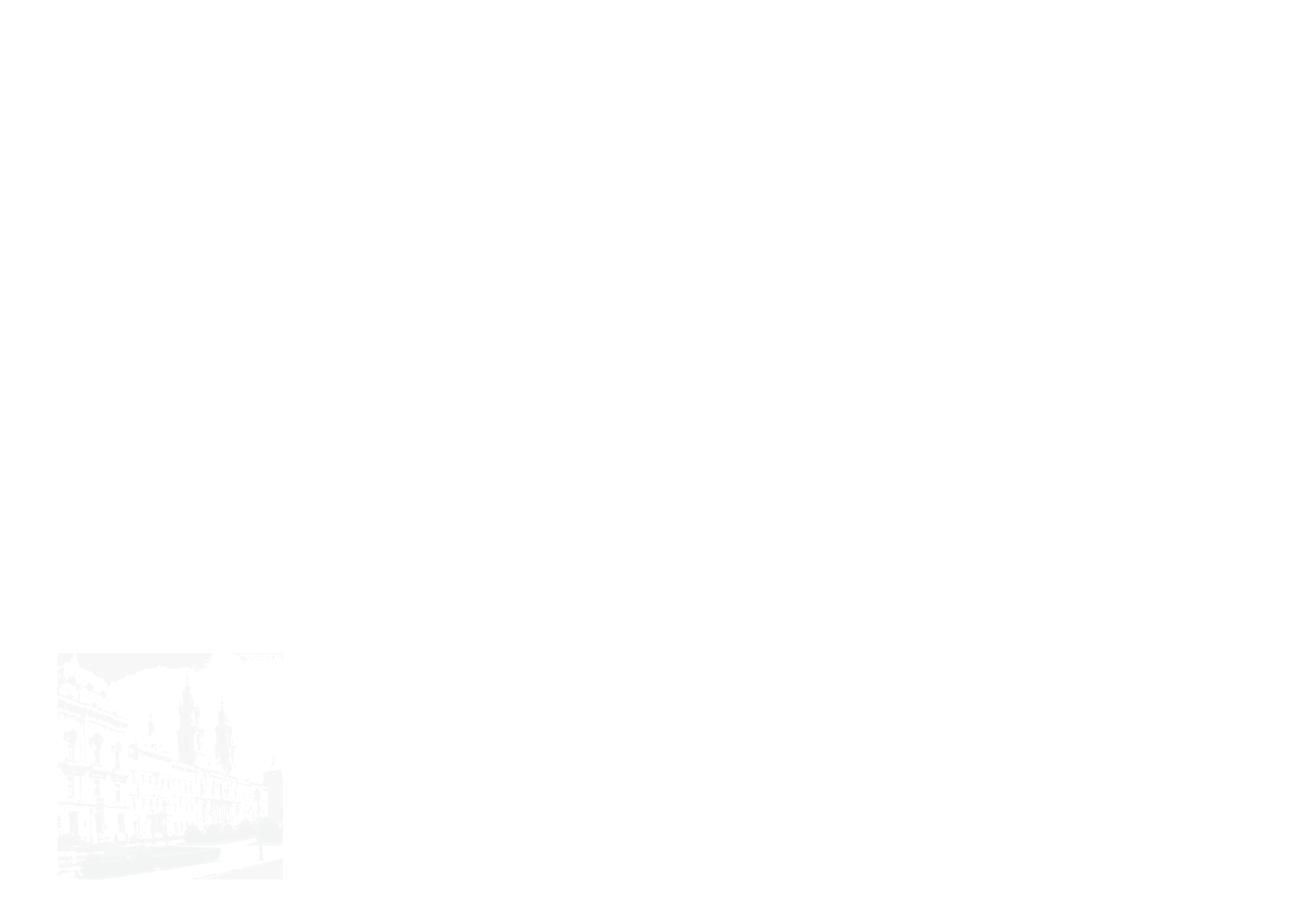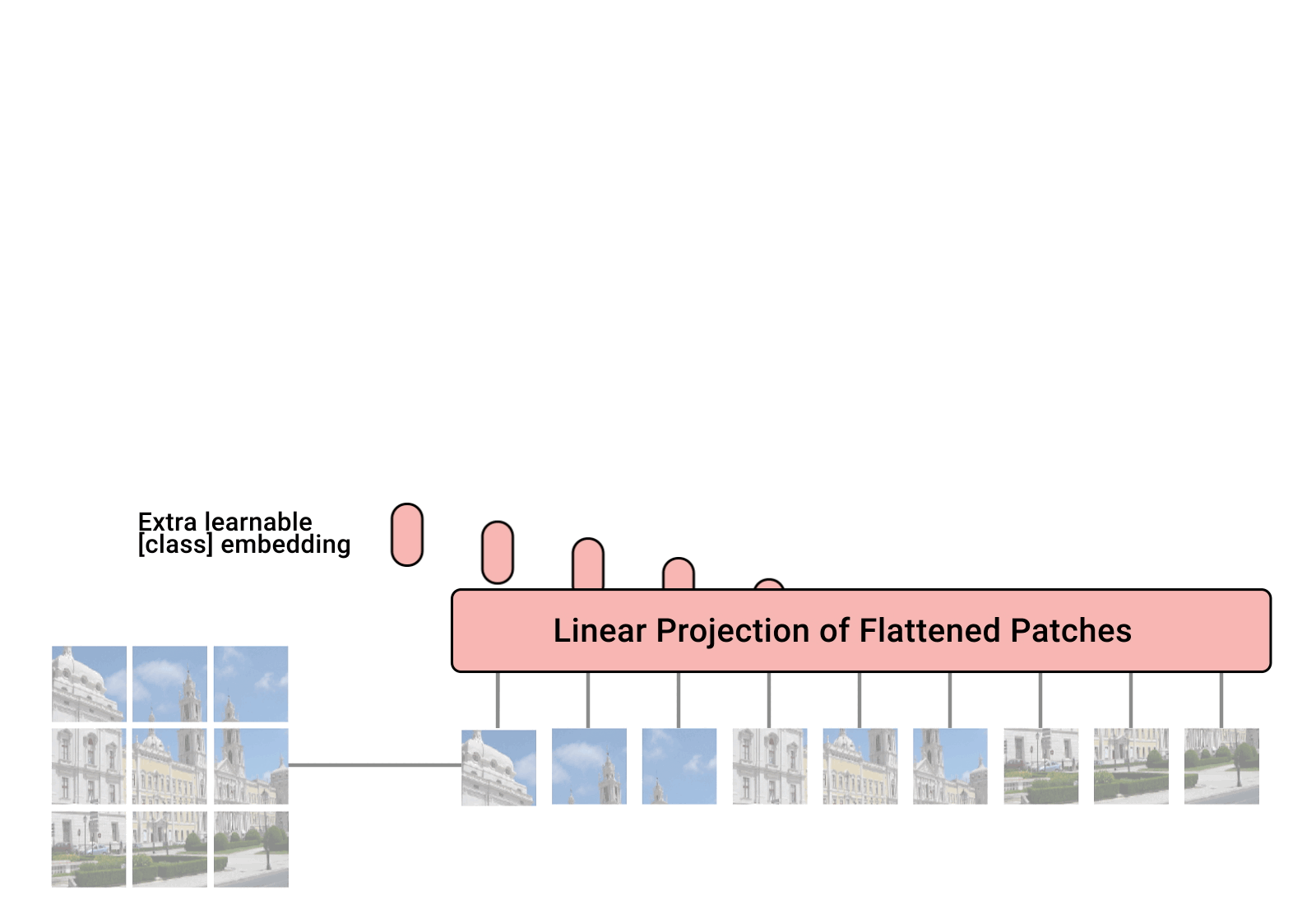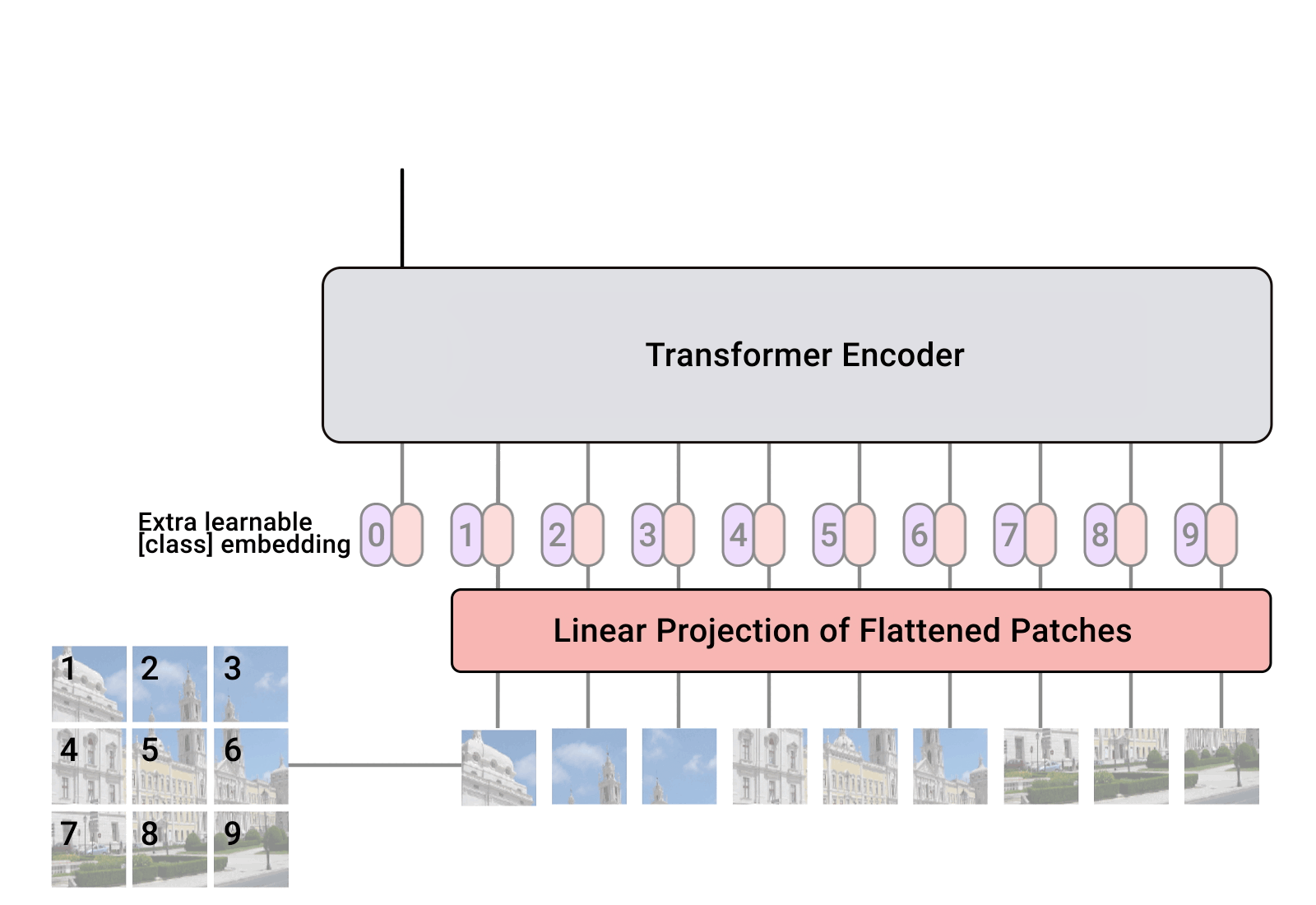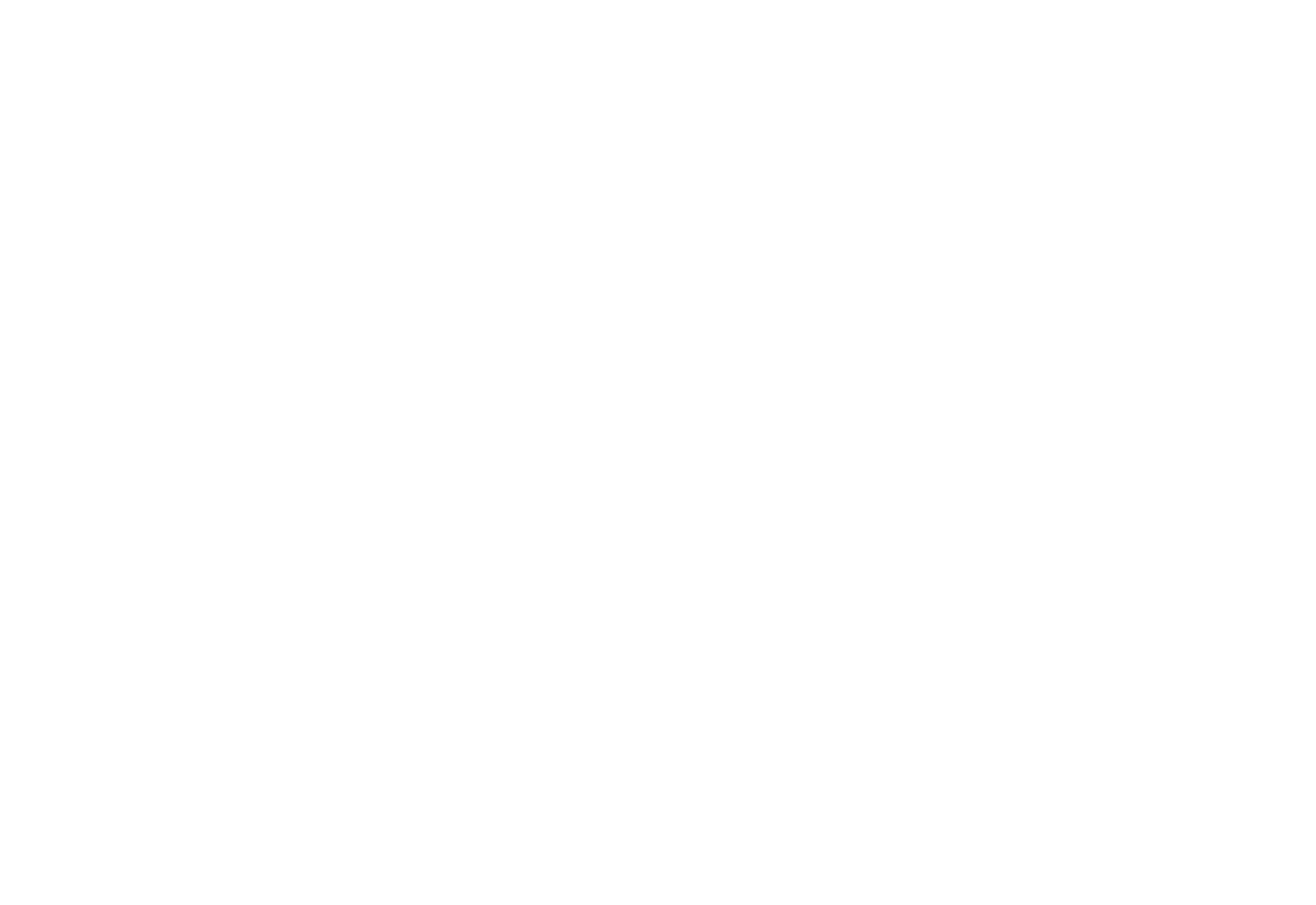
SepViT: Separable Vision Transformer
Vision Transformers have witnessed prevailing success in a series of vision tasks. However, these Transformers often rely on extensive computational costs to achieve high performance, which is burdensome to deploy on resource-constrained devices. To alleviate this issue, we draw lessons from depthwise separable convolution and imitate its ideology to design an efficient Transformer backbone, i.e., Separable Vision Transformer, abbreviated as SepViT. SepViT helps to carry out the local-global information interaction within and among the windows in sequential order via a depthwise separable self-attention. The novel window token embedding and grouped self-attention are employed to compute the attention relationship among windows with negligible cost and establish long-range visual interactions across multiple windows, respectively. Extensive experiments on general-purpose vision benchmarks demonstrate that SepViT can achieve a state-of-the-art trade-off between performance and latency. Among them, SepViT achieves 84.2% top-1 accuracy on ImageNet-1K classification while decreasing the latency by 40%, compared to the ones with similar accuracy (e.g., CSWin). Furthermore, SepViT achieves 51.0% mIoU on ADE20K semantic segmentation task, 47.9 AP on the RetinaNet-based COCO detection task, 49.4 box AP and 44.6 mask AP on Mask R-CNN-based COCO object detection and instance segmentation tasks.
PDF Abstract



