Semi-Supervised Monaural Singing Voice Separation With a Masking Network Trained on Synthetic Mixtures
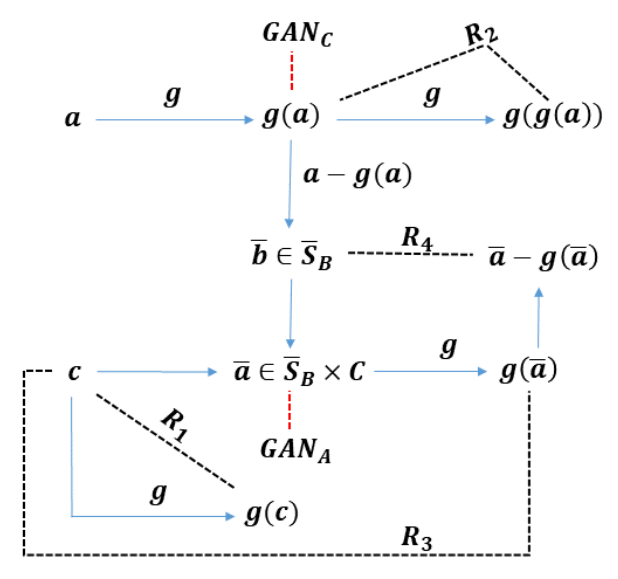
We study the problem of semi-supervised singing voice separation, in which the training data contains a set of samples of mixed music (singing and instrumental) and an unmatched set of instrumental music. Our solution employs a single mapping function g, which, applied to a mixed sample, recovers the underlying instrumental music, and, applied to an instrumental sample, returns the same sample. The network g is trained using purely instrumental samples, as well as on synthetic mixed samples that are created by mixing reconstructed singing voices with random instrumental samples. Our results indicate that we are on a par with or better than fully supervised methods, which are also provided with training samples of unmixed singing voices, and are better than other recent semi-supervised methods.
PDF Abstract


 MUSDB18
MUSDB18
