Semantic-aware Message Broadcasting for Efficient Unsupervised Domain Adaptation
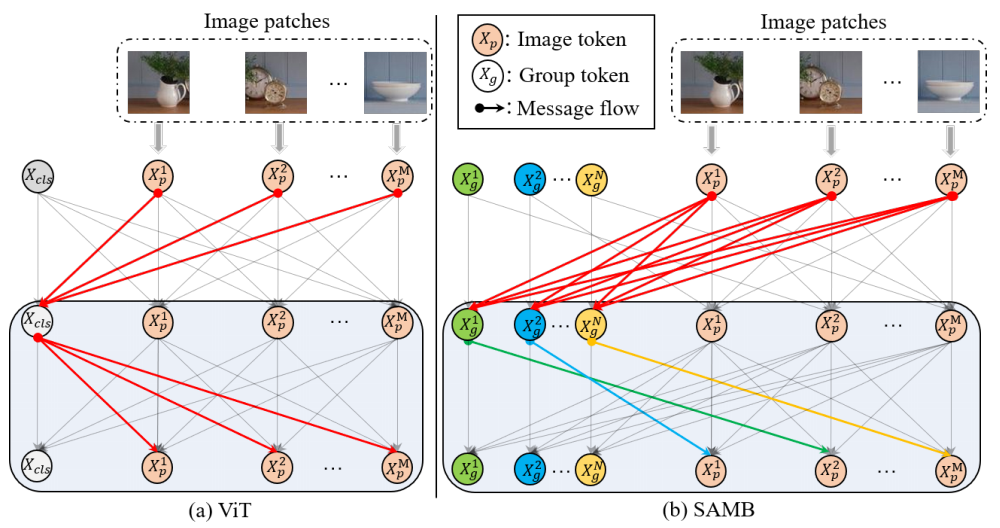
Vision transformer has demonstrated great potential in abundant vision tasks. However, it also inevitably suffers from poor generalization capability when the distribution shift occurs in testing (i.e., out-of-distribution data). To mitigate this issue, we propose a novel method, Semantic-aware Message Broadcasting (SAMB), which enables more informative and flexible feature alignment for unsupervised domain adaptation (UDA). Particularly, we study the attention module in the vision transformer and notice that the alignment space using one global class token lacks enough flexibility, where it interacts information with all image tokens in the same manner but ignores the rich semantics of different regions. In this paper, we aim to improve the richness of the alignment features by enabling semantic-aware adaptive message broadcasting. Particularly, we introduce a group of learned group tokens as nodes to aggregate the global information from all image tokens, but encourage different group tokens to adaptively focus on the message broadcasting to different semantic regions. In this way, our message broadcasting encourages the group tokens to learn more informative and diverse information for effective domain alignment. Moreover, we systematically study the effects of adversarial-based feature alignment (ADA) and pseudo-label based self-training (PST) on UDA. We find that one simple two-stage training strategy with the cooperation of ADA and PST can further improve the adaptation capability of the vision transformer. Extensive experiments on DomainNet, OfficeHome, and VisDA-2017 demonstrate the effectiveness of our methods for UDA.
PDF Abstract


 Office-Home
Office-Home
 DomainNet
DomainNet
 VisDA-2017
VisDA-2017

