Self-Tuning for Data-Efficient Deep Learning
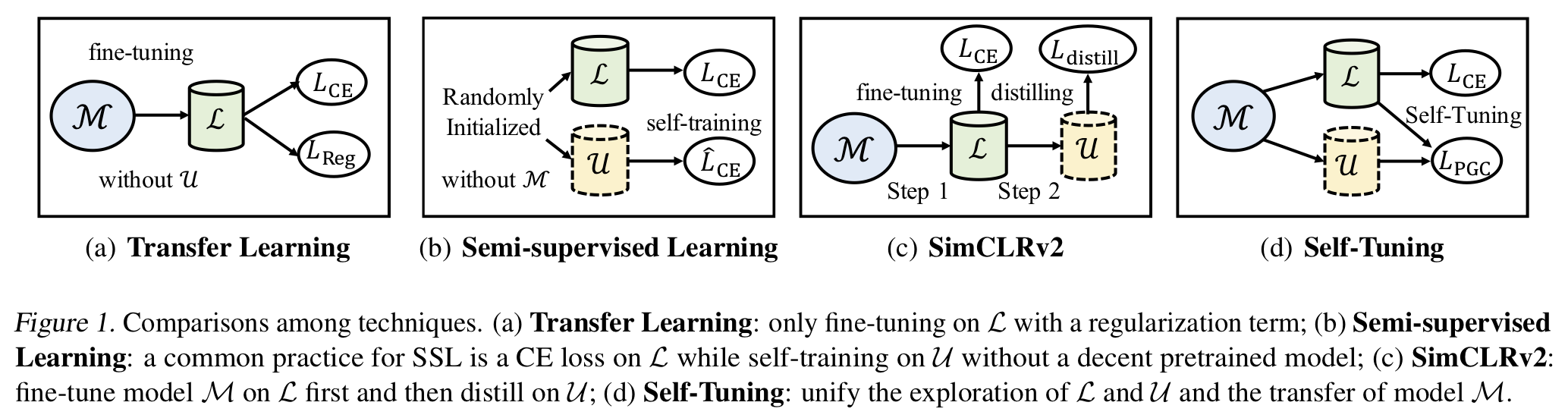
Deep learning has made revolutionary advances to diverse applications in the presence of large-scale labeled datasets. However, it is prohibitively time-costly and labor-expensive to collect sufficient labeled data in most realistic scenarios. To mitigate the requirement for labeled data, semi-supervised learning (SSL) focuses on simultaneously exploring both labeled and unlabeled data, while transfer learning (TL) popularizes a favorable practice of fine-tuning a pre-trained model to the target data. A dilemma is thus encountered: Without a decent pre-trained model to provide an implicit regularization, SSL through self-training from scratch will be easily misled by inaccurate pseudo-labels, especially in large-sized label space; Without exploring the intrinsic structure of unlabeled data, TL through fine-tuning from limited labeled data is at risk of under-transfer caused by model shift. To escape from this dilemma, we present Self-Tuning to enable data-efficient deep learning by unifying the exploration of labeled and unlabeled data and the transfer of a pre-trained model, as well as a Pseudo Group Contrast (PGC) mechanism to mitigate the reliance on pseudo-labels and boost the tolerance to false labels. Self-Tuning outperforms its SSL and TL counterparts on five tasks by sharp margins, e.g. it doubles the accuracy of fine-tuning on Cars with 15% labels.
PDF Abstract

 ImageNet
ImageNet
 CIFAR-100
CIFAR-100
 CUB-200-2011
CUB-200-2011
 Stanford Cars
Stanford Cars
 FGVC-Aircraft
FGVC-Aircraft
