Self-training from Self-memory in Data-to-text Generation
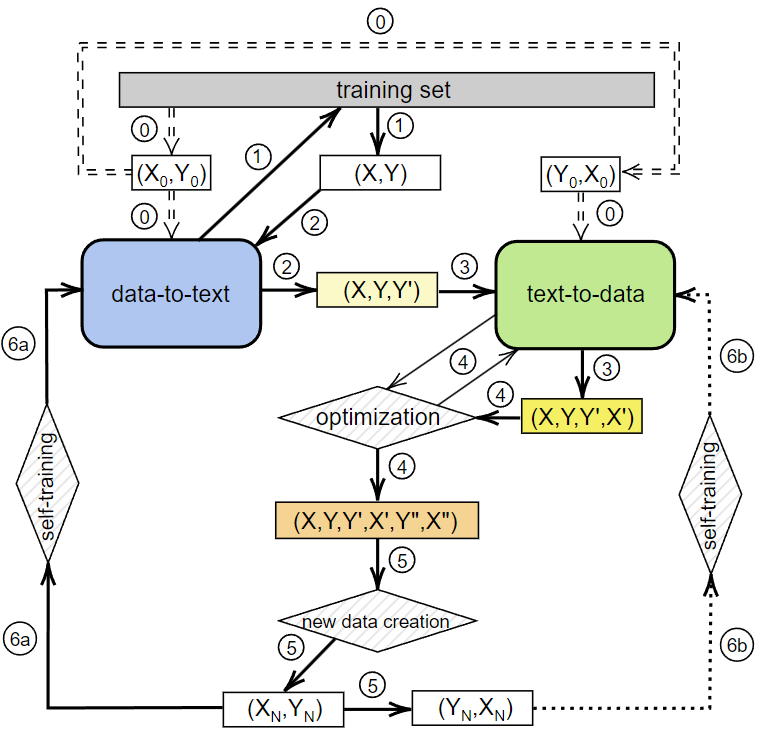
This paper introduces a novel training model, self-training from self-memory (STSM) in data-to-text generation (DTG), allowing the model to self-train on subsets, including self-memory as outputs inferred directly from the trained models and/or the new data. The quality of self-memory is validated by two models, data-to-text (D2T) and text-to-data (T2D), by two pre-defined conditions: (1) the appearance of all source values in the outputs of the D2T model and (2) the ability to convert back to source data in the outputs in the T2D model. We utilize a greedy algorithm to generate shorter D2T outputs if they contain all source values. Subsequently, we use the T2D model to confirm that these outputs can capture input relationships by demonstrating their capacity to convert text back into data. With 30% of the dataset, we can train the D2T model with a competitive performance compared to full training in the same setup. We experiment with our model on two datasets, E2E NLG and DART. STSM offers the D2T model a generalization capability from its subset memory while reducing training data volume. Ultimately, we anticipate that this paper will contribute to continual learning solutions that adapt to new training data, incorporating it as a form of self-memory in DTG tasks. The curated dataset is publicly available at: https://github.com/hoangthangta/STSM.
PDF Abstract




| Task | Dataset | Model | Metric Name | Metric Value | Global Rank | Benchmark |
|---|---|---|---|---|---|---|
| Data-to-Text Generation | DART | self-mem + new data | BLEU | 47.76 | # 1 | |
| Data-to-Text Generation | E2E | self-mem + new data (random) | METEOR | 46.11 | # 1 | |
| Data-to-Text Generation | E2E | self-mem + new data (fixed) | METEOR | 46.07 | # 2 | |
| Data-to-Text Generation | E2E NLG Challenge | Self-memory | BLEU | 65.11 | # 9 | |
| NIST | 8.35 | # 7 | ||||
| METEOR | 46.11 | # 1 | ||||
| ROUGE-L | 68.41 | # 6 | ||||
| CIDEr | 2.16 | # 7 |
