Self-supervised Video Representation Learning by Pace Prediction
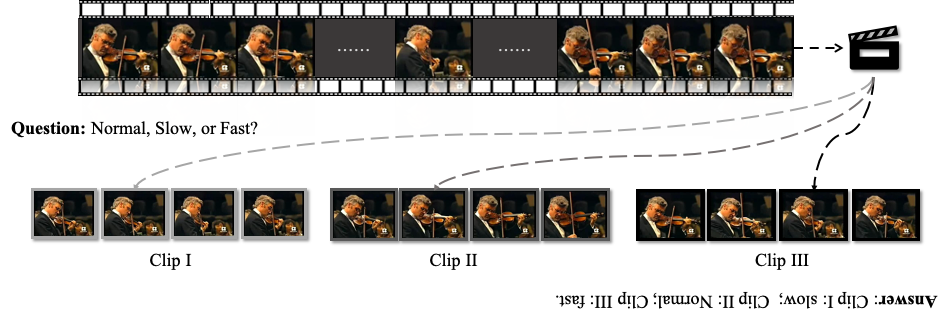
This paper addresses the problem of self-supervised video representation learning from a new perspective -- by video pace prediction. It stems from the observation that human visual system is sensitive to video pace, e.g., slow motion, a widely used technique in film making. Specifically, given a video played in natural pace, we randomly sample training clips in different paces and ask a neural network to identify the pace for each video clip. The assumption here is that the network can only succeed in such a pace reasoning task when it understands the underlying video content and learns representative spatio-temporal features. In addition, we further introduce contrastive learning to push the model towards discriminating different paces by maximizing the agreement on similar video content. To validate the effectiveness of the proposed method, we conduct extensive experiments on action recognition and video retrieval tasks with several alternative network architectures. Experimental evaluations show that our approach achieves state-of-the-art performance for self-supervised video representation learning across different network architectures and different benchmarks. The code and pre-trained models are available at https://github.com/laura-wang/video-pace.
PDF Abstract ECCV 2020 PDF ECCV 2020 Abstract




