Self-Supervised Pillar Motion Learning for Autonomous Driving
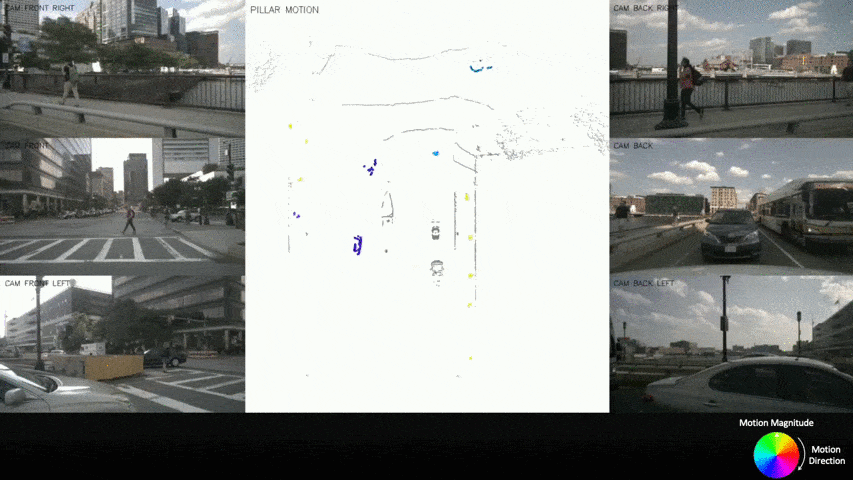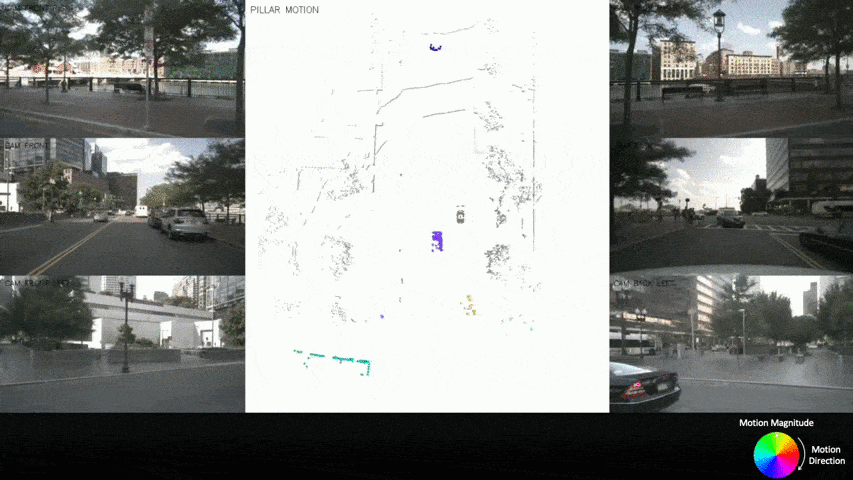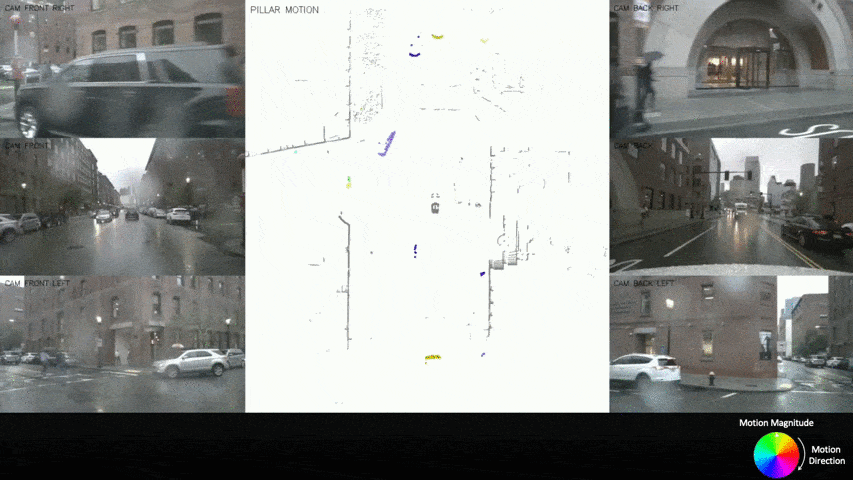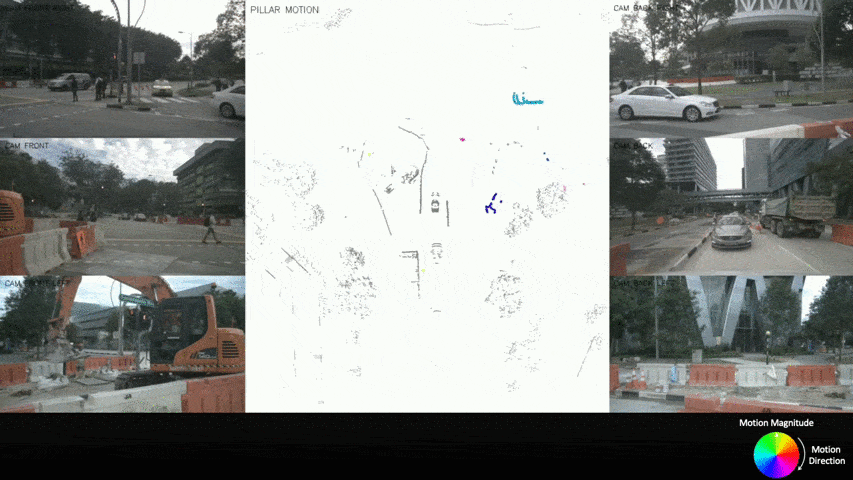
Autonomous driving can benefit from motion behavior comprehension when interacting with diverse traffic participants in highly dynamic environments. Recently, there has been a growing interest in estimating class-agnostic motion directly from point clouds. Current motion estimation methods usually require vast amount of annotated training data from self-driving scenes. However, manually labeling point clouds is notoriously difficult, error-prone and time-consuming. In this paper, we seek to answer the research question of whether the abundant unlabeled data collections can be utilized for accurate and efficient motion learning. To this end, we propose a learning framework that leverages free supervisory signals from point clouds and paired camera images to estimate motion purely via self-supervision. Our model involves a point cloud based structural consistency augmented with probabilistic motion masking as well as a cross-sensor motion regularization to realize the desired self-supervision. Experiments reveal that our approach performs competitively to supervised methods, and achieves the state-of-the-art result when combining our self-supervised model with supervised fine-tuning.
PDF Abstract CVPR 2021 PDF CVPR 2021 Abstract


 KITTI
KITTI
 nuScenes
nuScenes
 FlyingThings3D
FlyingThings3D
