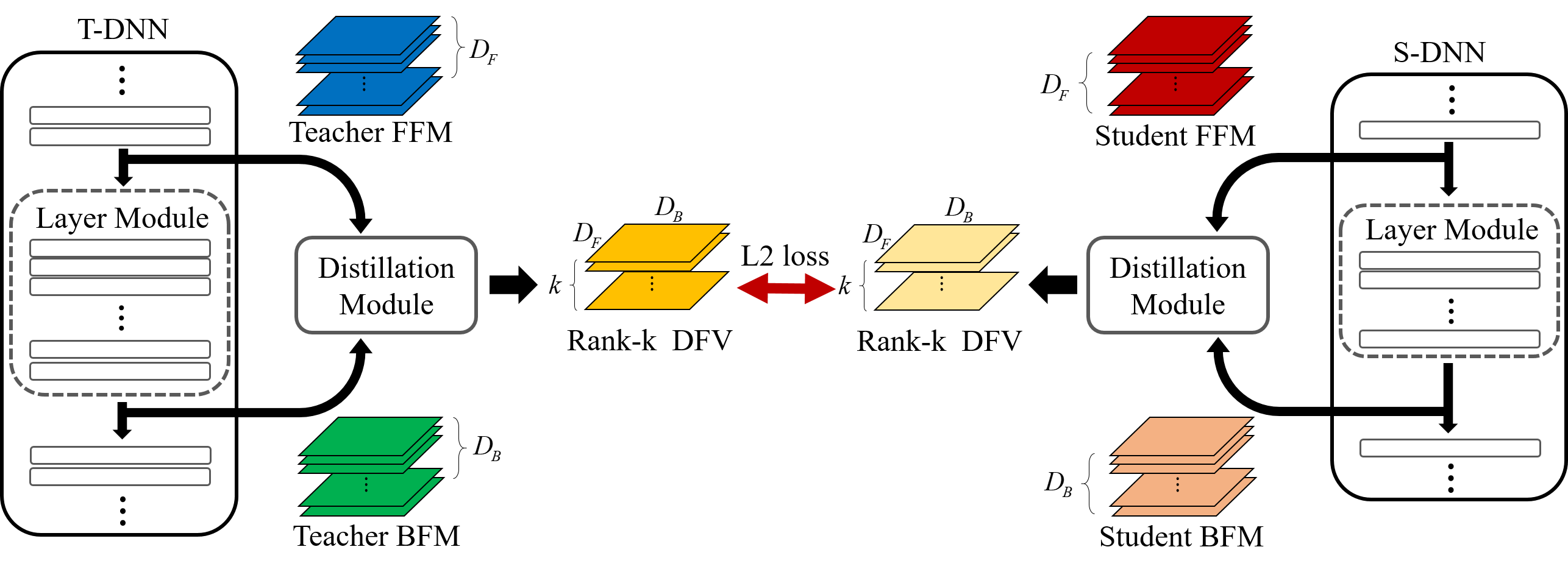
Self-supervised Knowledge Distillation Using Singular Value Decomposition
To solve deep neural network (DNN)'s huge training dataset and its high computation issue, so-called teacher-student (T-S) DNN which transfers the knowledge of T-DNN to S-DNN has been proposed. However, the existing T-S-DNN has limited range of use, and the knowledge of T-DNN is insufficiently transferred to S-DNN. To improve the quality of the transferred knowledge from T-DNN, we propose a new knowledge distillation using singular value decomposition (SVD). In addition, we define a knowledge transfer as a self-supervised task and suggest a way to continuously receive information from T-DNN. Simulation results show that a S-DNN with a computational cost of 1/5 of the T-DNN can be up to 1.1\% better than the T-DNN in terms of classification accuracy. Also assuming the same computational cost, our S-DNN outperforms the S-DNN driven by the state-of-the-art distillation with a performance advantage of 1.79\%. code is available on https://github.com/sseung0703/SSKD\_SVD.
PDF Abstract ECCV 2018 PDF ECCV 2018 Abstract


 CIFAR-100
CIFAR-100
 ImageNet-32
ImageNet-32
