Self-supervised 3D anatomy segmentation using self-distilled masked image transformer (SMIT)
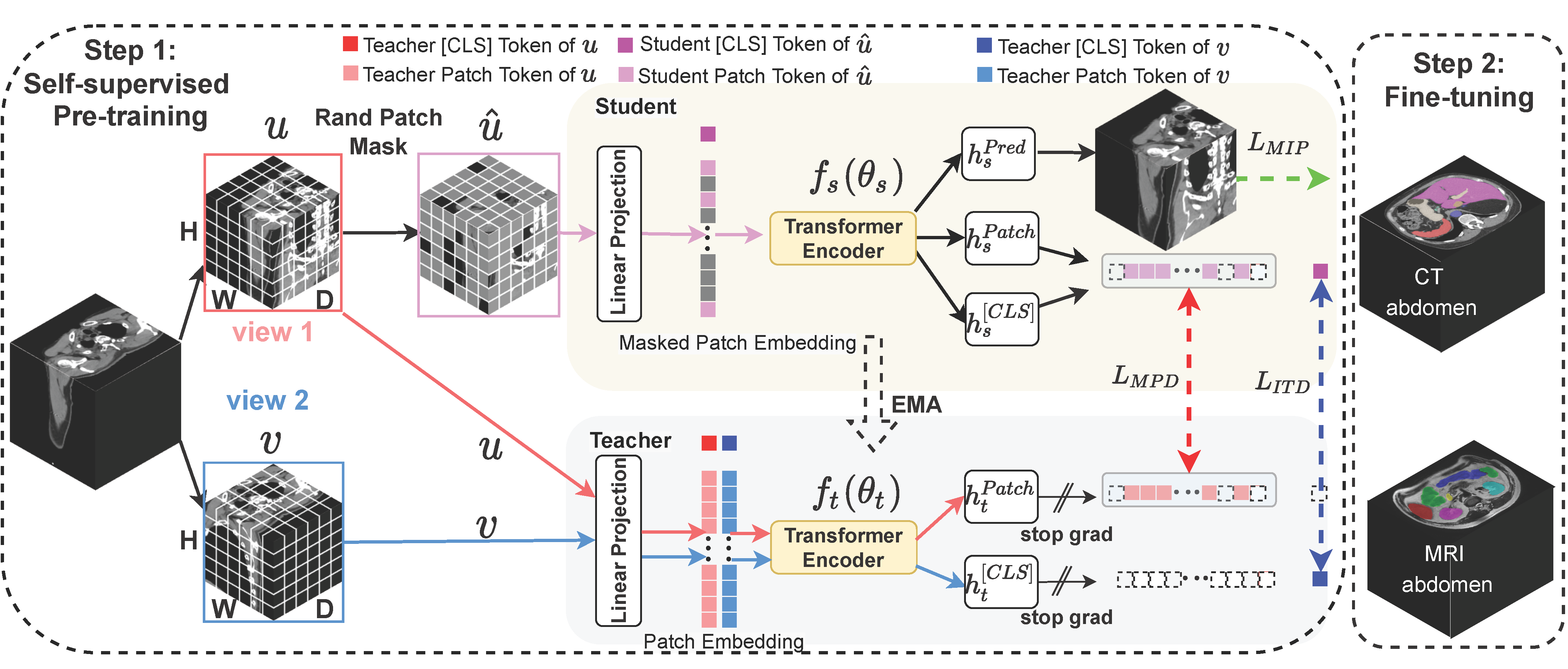
Vision transformers, with their ability to more efficiently model long-range context, have demonstrated impressive accuracy gains in several computer vision and medical image analysis tasks including segmentation. However, such methods need large labeled datasets for training, which is hard to obtain for medical image analysis. Self-supervised learning (SSL) has demonstrated success in medical image segmentation using convolutional networks. In this work, we developed a \underline{s}elf-distillation learning with \underline{m}asked \underline{i}mage modeling method to perform SSL for vision \underline{t}ransformers (SMIT) applied to 3D multi-organ segmentation from CT and MRI. Our contribution is a dense pixel-wise regression within masked patches called masked image prediction, which we combined with masked patch token distillation as pretext task to pre-train vision transformers. We show our approach is more accurate and requires fewer fine tuning datasets than other pretext tasks. Unlike prior medical image methods, which typically used image sets arising from disease sites and imaging modalities corresponding to the target tasks, we used 3,643 CT scans (602,708 images) arising from head and neck, lung, and kidney cancers as well as COVID-19 for pre-training and applied it to abdominal organs segmentation from MRI pancreatic cancer patients as well as publicly available 13 different abdominal organs segmentation from CT. Our method showed clear accuracy improvement (average DSC of 0.875 from MRI and 0.878 from CT) with reduced requirement for fine-tuning datasets over commonly used pretext tasks. Extensive comparisons against multiple current SSL methods were done. Code will be made available upon acceptance for publication.
PDF Abstract




