Self-Improvement for Neural Combinatorial Optimization: Sample without Replacement, but Improvement
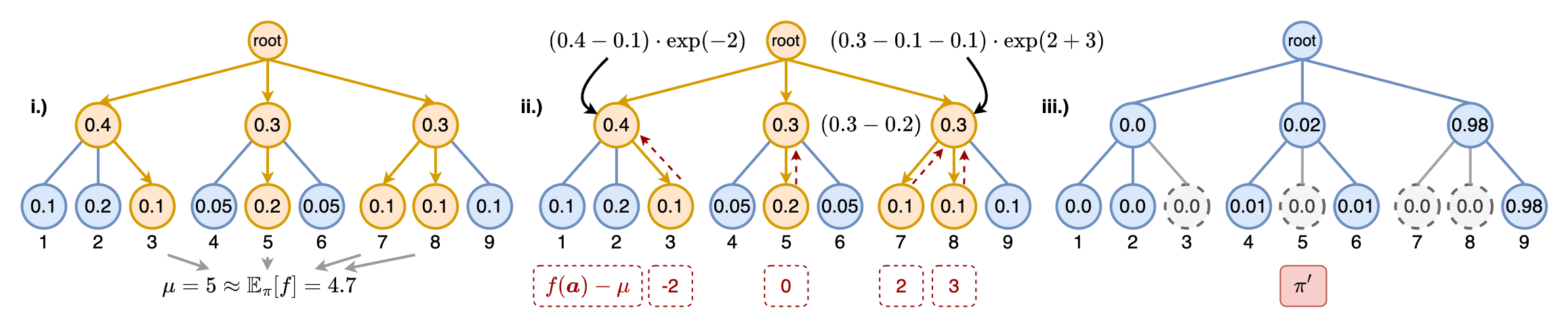
Current methods for end-to-end constructive neural combinatorial optimization usually train a policy using behavior cloning from expert solutions or policy gradient methods from reinforcement learning. While behavior cloning is straightforward, it requires expensive expert solutions, and policy gradient methods are often computationally demanding and complex to fine-tune. In this work, we bridge the two and simplify the training process by sampling multiple solutions for random instances using the current model in each epoch and then selecting the best solution as an expert trajectory for supervised imitation learning. To achieve progressively improving solutions with minimal sampling, we introduce a method that combines round-wise Stochastic Beam Search with an update strategy derived from a provable policy improvement. This strategy refines the policy between rounds by utilizing the advantage of the sampled sequences with almost no computational overhead. We evaluate our approach on the Traveling Salesman Problem and the Capacitated Vehicle Routing Problem. The models trained with our method achieve comparable performance and generalization to those trained with expert data. Additionally, we apply our method to the Job Shop Scheduling Problem using a transformer-based architecture and outperform existing state-of-the-art methods by a wide margin.
PDF Abstract

