Self-distillation Regularized Connectionist Temporal Classification Loss for Text Recognition: A Simple Yet Effective Approach
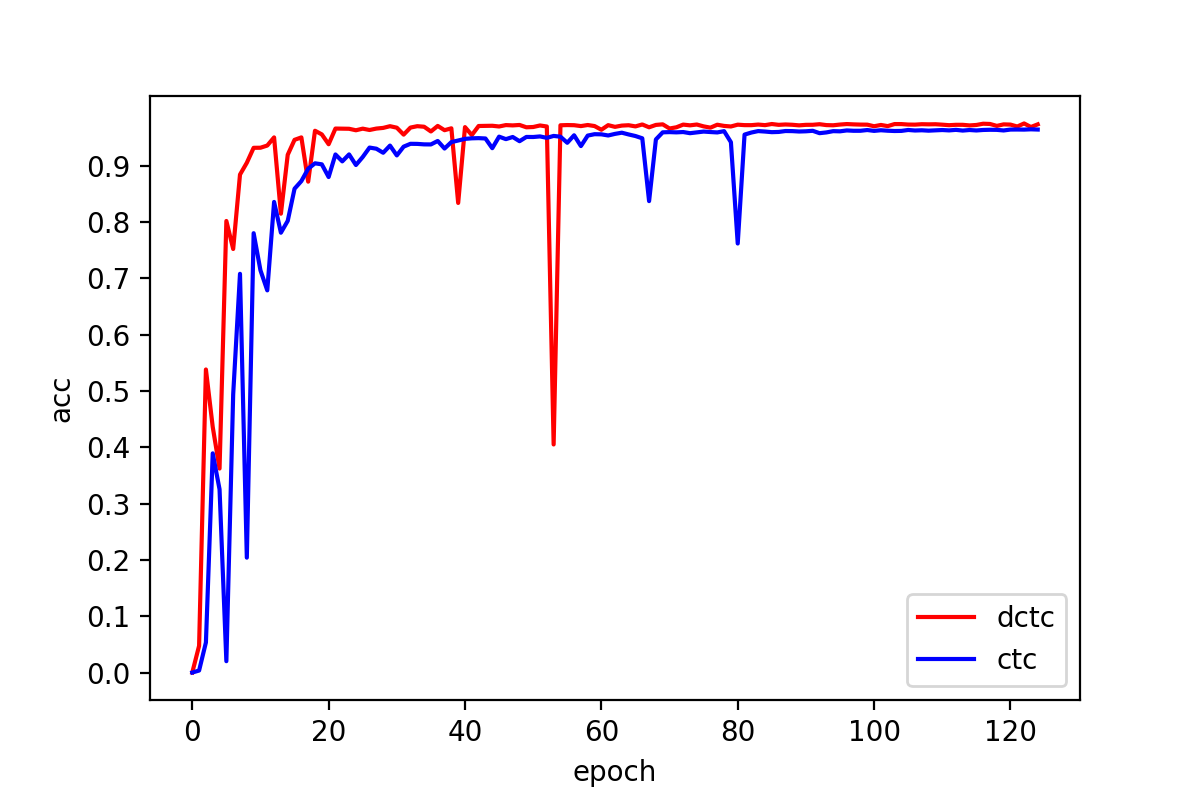
Text recognition methods are gaining rapid development. Some advanced techniques, e.g., powerful modules, language models, and un- and semi-supervised learning schemes, consecutively push the performance on public benchmarks forward. However, the problem of how to better optimize a text recognition model from the perspective of loss functions is largely overlooked. CTC-based methods, widely used in practice due to their good balance between performance and inference speed, still grapple with accuracy degradation. This is because CTC loss emphasizes the optimization of the entire sequence target while neglecting to learn individual characters. We propose a self-distillation scheme for CTC-based model to address this issue. It incorporates a framewise regularization term in CTC loss to emphasize individual supervision, and leverages the maximizing-a-posteriori of latent alignment to solve the inconsistency problem that arises in distillation between CTC-based models. We refer to the regularized CTC loss as Distillation Connectionist Temporal Classification (DCTC) loss. DCTC loss is module-free, requiring no extra parameters, longer inference lag, or additional training data or phases. Extensive experiments on public benchmarks demonstrate that DCTC can boost text recognition model accuracy by up to 2.6%, without any of these drawbacks.
PDF Abstract
