SEED RL: Scalable and Efficient Deep-RL with Accelerated Central Inference
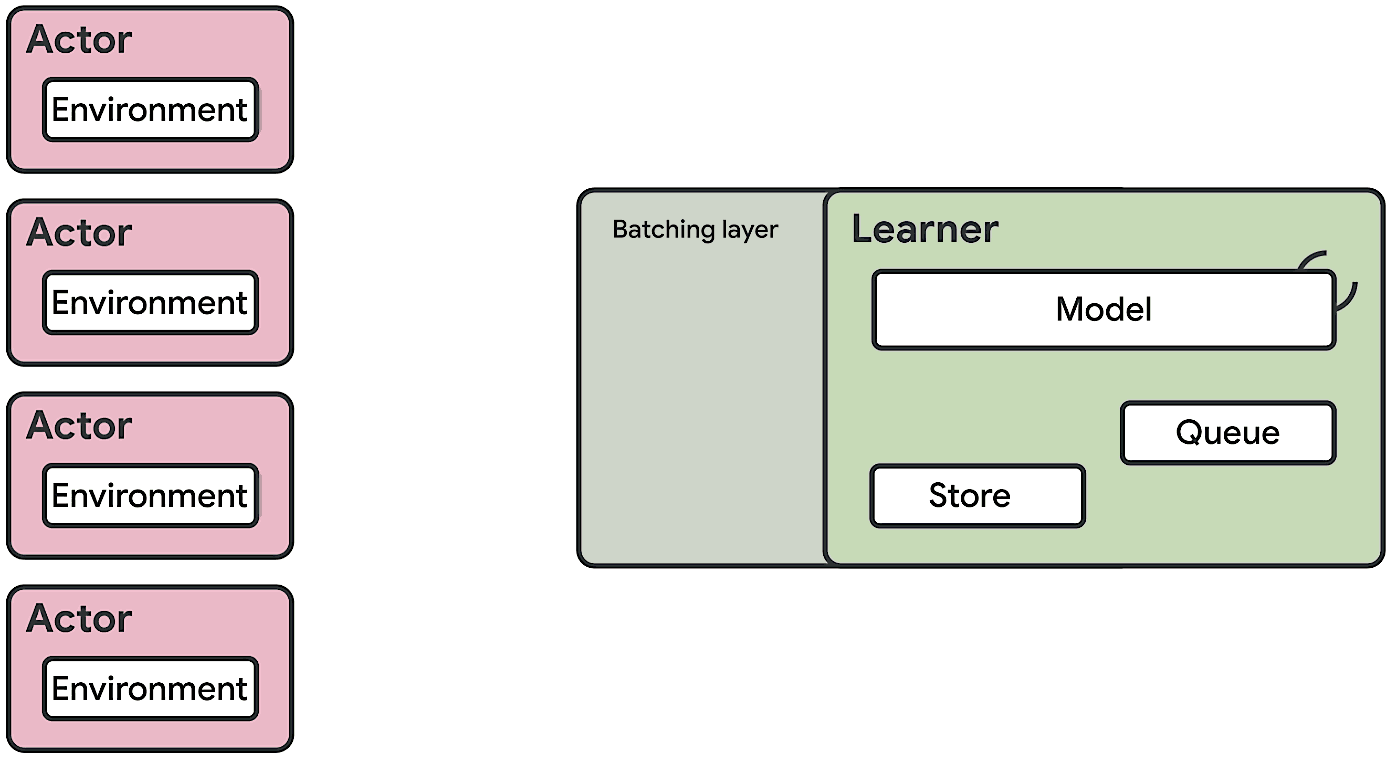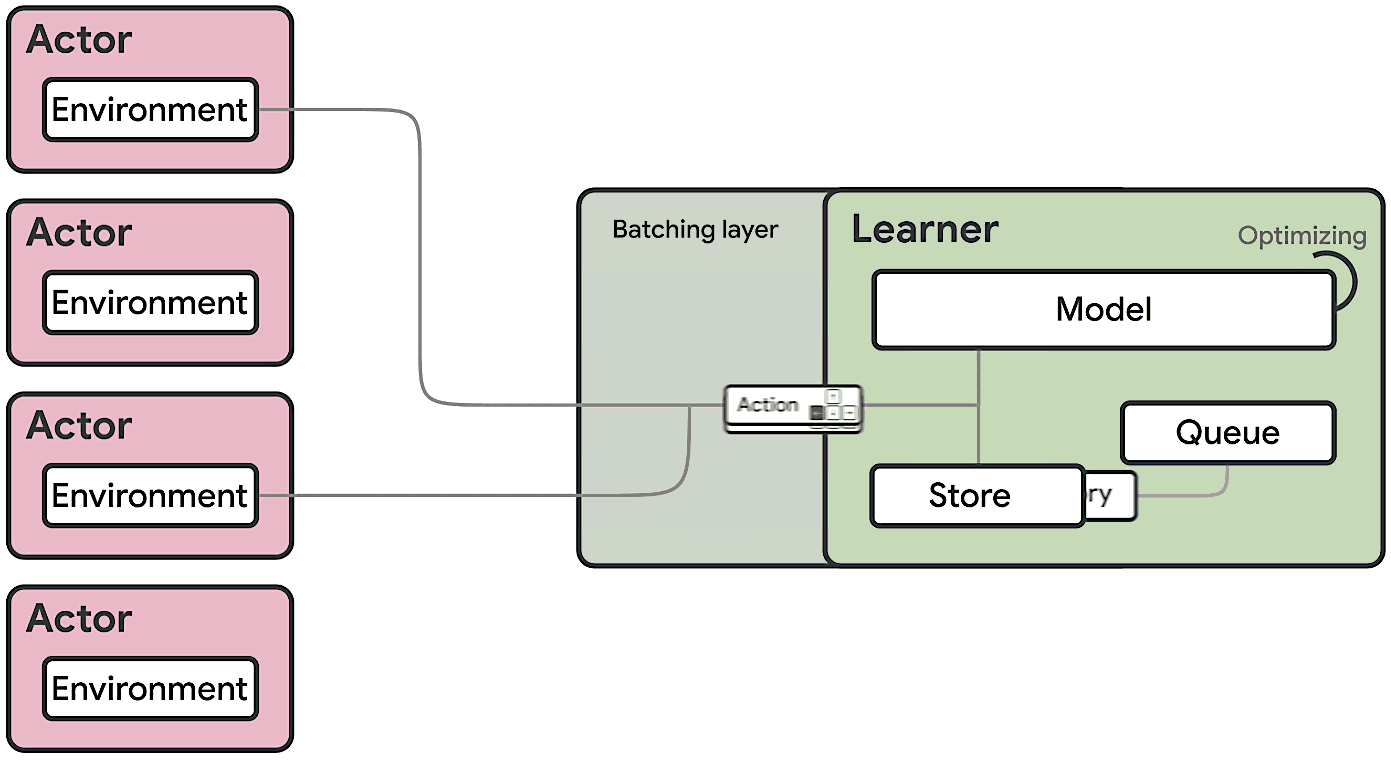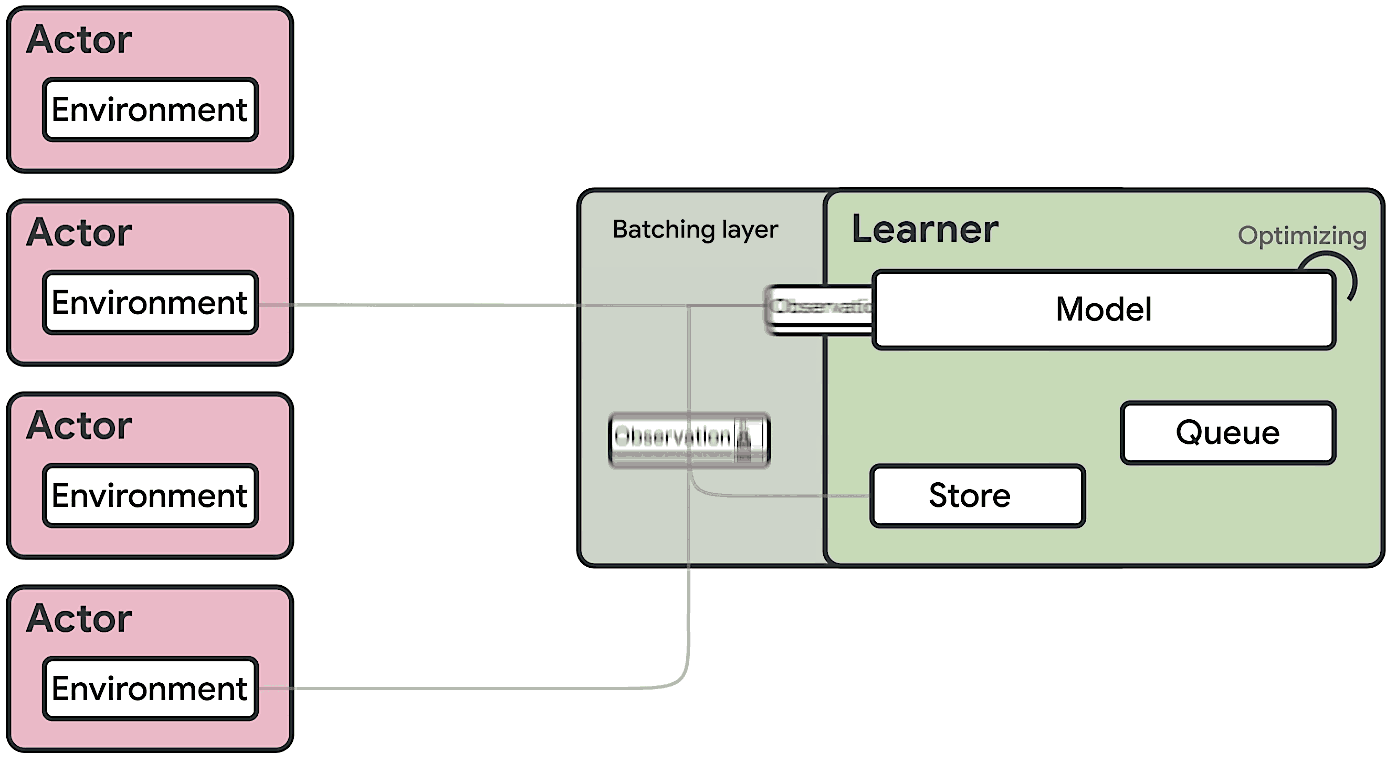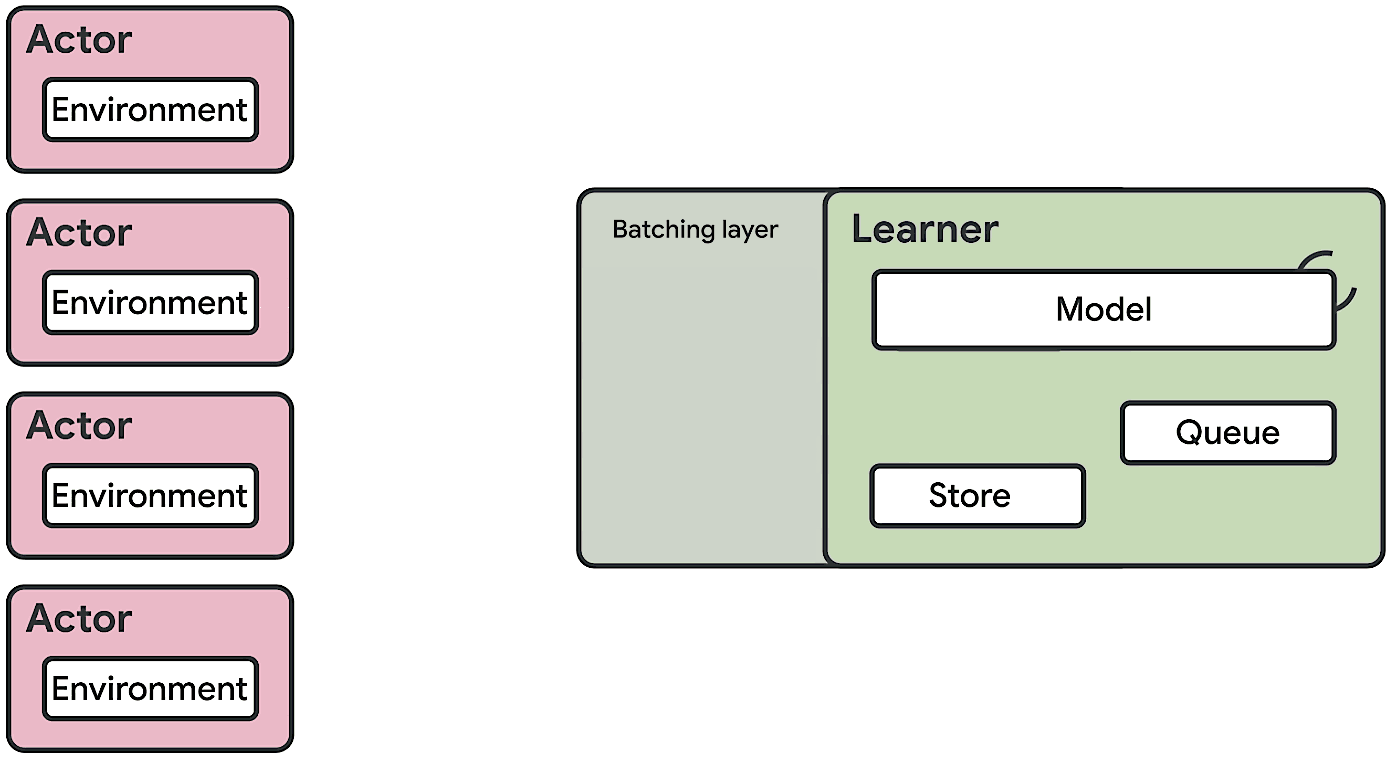
We present a modern scalable reinforcement learning agent called SEED (Scalable, Efficient Deep-RL). By effectively utilizing modern accelerators, we show that it is not only possible to train on millions of frames per second but also to lower the cost of experiments compared to current methods. We achieve this with a simple architecture that features centralized inference and an optimized communication layer. SEED adopts two state of the art distributed algorithms, IMPALA/V-trace (policy gradients) and R2D2 (Q-learning), and is evaluated on Atari-57, DeepMind Lab and Google Research Football. We improve the state of the art on Football and are able to reach state of the art on Atari-57 three times faster in wall-time. For the scenarios we consider, a 40% to 80% cost reduction for running experiments is achieved. The implementation along with experiments is open-sourced so results can be reproduced and novel ideas tried out.
PDF Abstract ICLR 2020 PDF ICLR 2020 Abstract
 Colab
Colab


 Arcade Learning Environment
Arcade Learning Environment
