SEED-Bench-2: Benchmarking Multimodal Large Language Models
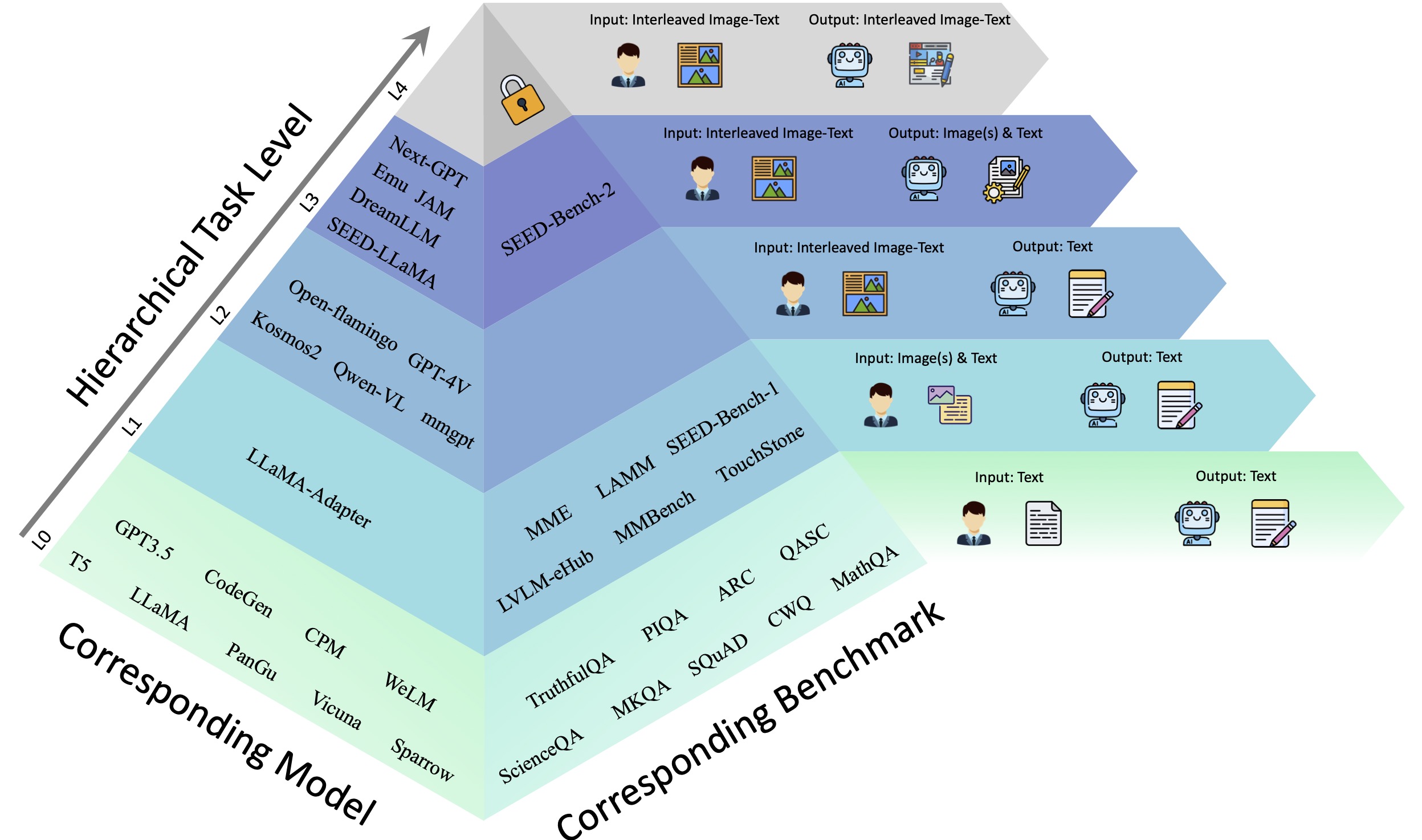
Multimodal large language models (MLLMs), building upon the foundation of powerful large language models (LLMs), have recently demonstrated exceptional capabilities in generating not only texts but also images given interleaved multimodal inputs (acting like a combination of GPT-4V and DALL-E 3). However, existing MLLM benchmarks remain limited to assessing only models' comprehension ability of single image-text inputs, failing to keep up with the strides made in MLLMs. A comprehensive benchmark is imperative for investigating the progress and uncovering the limitations of current MLLMs. In this work, we categorize the capabilities of MLLMs into hierarchical levels from $L_0$ to $L_4$ based on the modalities they can accept and generate, and propose SEED-Bench-2, a comprehensive benchmark that evaluates the \textbf{hierarchical} capabilities of MLLMs. Specifically, SEED-Bench-2 comprises 24K multiple-choice questions with accurate human annotations, which spans 27 dimensions, including the evaluation of both text and image generation. Multiple-choice questions with groundtruth options derived from human annotation enables an objective and efficient assessment of model performance, eliminating the need for human or GPT intervention during evaluation. We further evaluate the performance of 23 prominent open-source MLLMs and summarize valuable observations. By revealing the limitations of existing MLLMs through extensive evaluations, we aim for SEED-Bench-2 to provide insights that will motivate future research towards the goal of General Artificial Intelligence. Dataset and evaluation code are available at \href{https://github.com/AILab-CVC/SEED-Bench}
PDF Abstract Spaces
Spaces



 MMBench
MMBench
 SEED-Bench
SEED-Bench
