SDCOR: Scalable Density-based Clustering for Local Outlier Detection in Massive-Scale Datasets
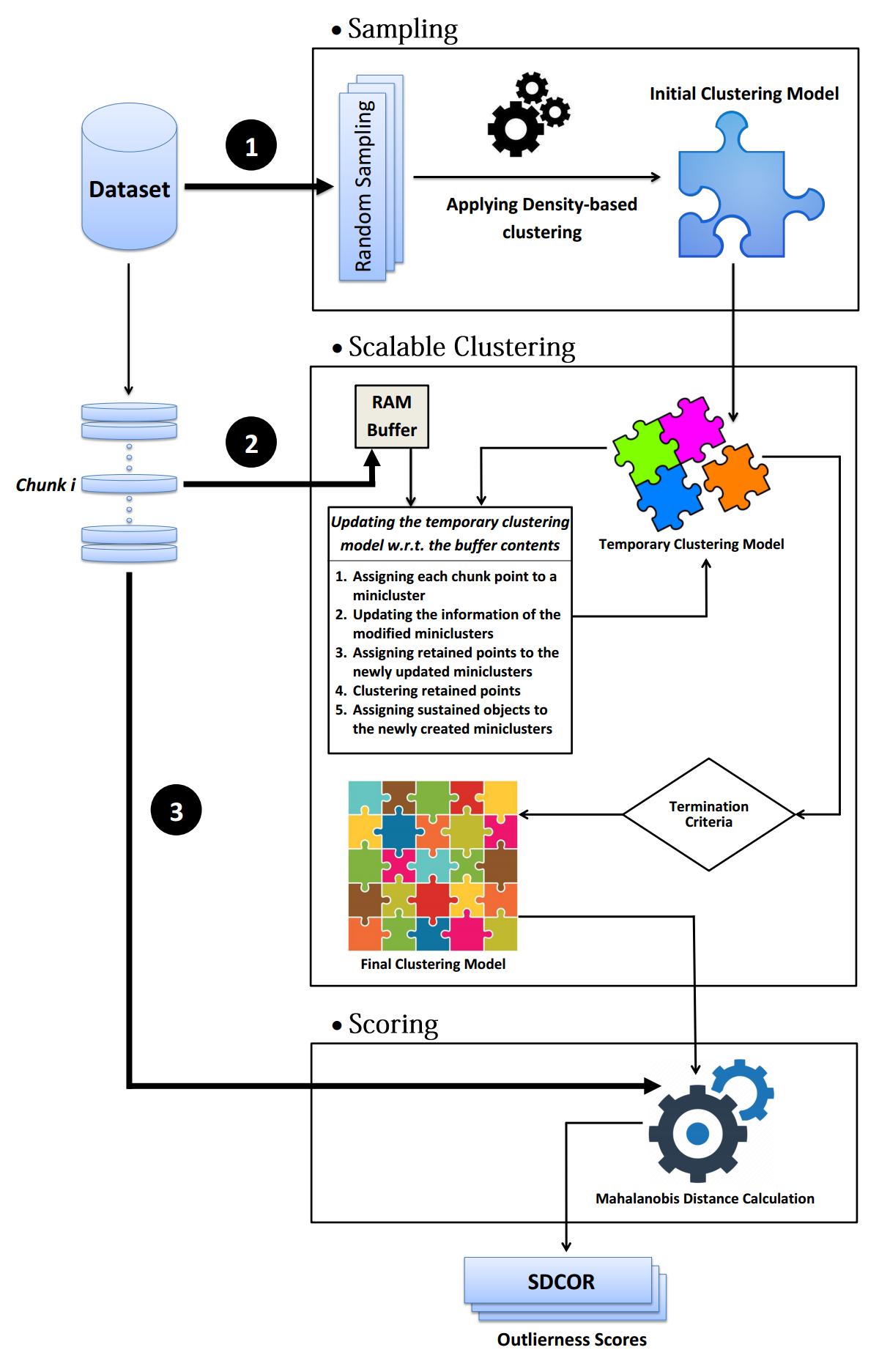
This paper presents a batch-wise density-based clustering approach for local outlier detection in massive-scale datasets. Unlike the well-known traditional algorithms, which assume that all the data is memory-resident, our proposed method is scalable and processes the input data chunk-by-chunk within the confines of a limited memory buffer. A temporary clustering model is built at the first phase; then, it is gradually updated by analyzing consecutive memory loads of points. Subsequently, at the end of scalable clustering, the approximate structure of the original clusters is obtained. Finally, by another scan of the entire dataset and using a suitable criterion, an outlying score is assigned to each object called SDCOR (Scalable Density-based Clustering Outlierness Ratio). Evaluations on real-life and synthetic datasets demonstrate that the proposed method has a low linear time complexity and is more effective and efficient compared to best-known conventional density-based methods, which need to load all data into the memory; and also, to some fast distance-based methods, which can perform on data resident in the disk.
PDF Abstract

